The Mosel Language
The Mosel language can be thought of as both a modeling language and a programming language. Like other modeling languages it offers the required facilities to declare and manipulate problems, decision variables, constraints and various data types and structures like sets and arrays. On the other hand, it also provides a complete set of functionalities proper to programming languages: it is compiled and optimized, all usual control flow constructs are supported (selection, loops) and can be extended by means of modules. Among these extensions, optimizers can be loaded just like any other type of modules and the functionality they offer may be used in the same way as any Mosel procedures or functions. These properties make of Mosel a powerful modeling, programming and solving language with which it is possible to write complex solution algorithms.
The syntax has been designed to be easy to learn and maintain. As a consequence, the set of reserved words and syntax constructs has deliberately been kept small avoiding shortcuts and `tricks' often provided by modeling languages. These facilities are sometimes useful to reduce the size of a model source (not its readability) but also are likely to introduce inconsistencies and ambiguities in the language itself, making it harder to understand and maintain.
Introduction
Comments
A comment is a part of the source file that is ignored by the compiler. It is usually used to explain what the program is supposed to do. Either single line comments or multi lines comments can be used in a source file. For the first case, the comment starts with the '!' character and terminates with the end of the line. A multi-line commentary must be inclosed in '(!' and '!)'. Note that it is possible to nest several multi-line commentaries.
! In a comment This text will be analyzed (! Start of a multi line (! Another comment blabla end of the second level comment !) end of the first level !) Analysis continues here
Comments may appear anywhere in the source file.
Identifiers
Identifiers are used to name objects (variables, for instance). An identifier is an alphanumeric (plus '_') character string starting with an alphabetic character or '_'. All characters of an identifier are significant and the case is important (the identifier 'word' is not equivalent to 'Word').
Reserved words
The reserved words are identifiers with a particular meaning that determine a specific behaviour within the language. Because of their special role, these keywords cannot be used to name user defined objects (i.e. they cannot be redefined). The list of reserved words is:
and, array, as, boolean, break, case, declarations, div, do, mpvar, dynamic, elif, else, end, false, forall, forward, from, function, if, imports, in, include, initialisations, initializations, integer, inter, is_binary, is_continuous, is_free, is_integer, is_partint, is_semcont, is_semint, is_sos1, is_sos2, linctr, list, max, min, mod, model, next, not, of, options, or, package, parameters, procedure, public, prod, range, real, record, repeat, requirements, set, string, sum, then, to, true, union, until, uses, version, while.
Note that, although the lexical analyzer of Mosel is case-sensitive, the reserved words are defined both as lower and upper case (i.e. AND and and are keywords but not And).
Separation of instructions, line breaking
In order to improve the readability of the source code, each statement may be split across several lines and indented using as many spaces or tabulations as required. However, as the line breaking is the expression terminator, if an expression is to be split, it must be cut after a symbol that implies a continuation like an operator ('+', '-', ...) or a comma (',') in order to warn the analyzer that the expression continues in the following line(s).
A+B ! Expression 1 -C+D ! Expression 2 A+B- ! Expression 3... C+D ! ...end of expression 3
Moreover, the character ';' can be used as an expression terminator.
A+B ; -C+D ! 2 expressions on the same line
Some users prefer to explicitly mark the end of each expression with a particular symbol. This is possible using the option explterm (see Section The compiler directives) which disables the default behaviour of the compiler. In that case, the line breaking is not considered any more as an expression separator and each statement finishing with an expression must be terminated by the symbol ';'.
A+B; ! Expression 1 -C+D; ! Expression 2 A+B ! Expression 3... -C+D; ! ...end of expression 3
Conventions in this document
In the following sections, the language syntax is explained. In all code templates, the following conventions are employed:
- word: 'word' is a keyword and should be typed as is;
- todo: 'todo' is to be replaced by something else that is explained later;
- [ something ]: 'something' is optional and the entire block of instructions may be omitted;
- [ something ...]: 'something' is optional but if used, it can be repeated several times.
Structure of the source file
The Mosel compiler may compile both models and packages source files. Once compiled, a model is ready for execution but a package is intended to be used by a model or another package (see Section The compiler directives).
The general structure of a model source file is as follows:
| model model_name [ Directives ] [ Parameters ] [ Body ] end-model |
The model statement marks the beginning the program and the statement end-model its end. Any text following this instruction is ignored (this can be used for adding plain text comments after the end of the program). The model name may be any quoted string or identifier, this name will be used as the model name in the Mosel model manager. An optional set of directives and a parameters block may follow. The actual program/model is described in the body of the source file which consists of a succession of declaration blocks, subroutine definitions and statements.
The structure of a package (see Section Packages) source file is similar to the one of a model:
| package package_name [ Directives ] [ Parameters ] [ Body ] end-package |
The package statement marks the beginning the library and the statement end-package its end. The package name must be a valid identifier.
It is important to understand that the language is procedural and not declarative: the declarations and statements are compiled and executed in the order of their appearance. As a consequence, it is not possible to refer to an identifier that is declared later in the source file or consider that a statement located later in the source file has already been executed. Moreover, the language is compiled and not interpreted: the entire source file is first translated — as a whole — into a binary form (the BIM file), then this binary form of the program is read again to be executed. During the compilation, except for some simple constant expressions, no action is actually performed. This is why only some errors can be detected during the compilation time, any others being detected when running the program.
The compiler directives
The compiler accepts four different types of directives: the uses statement, the imports statement, the options statement and the version statement.
Directive uses
The general form of a uses statement is:
| uses libname1 [, libname2 ...][;] |
This clause asks the compiler to load the listed modules or packages and import the symbols they define. Modules must still be available for running the model but packages are incorporated into the generated bim file when compiling a model. If the source file being processed is a package, the bim files associated to the listed packages must be available for compiling another file using this package. It is also possible to merge bim files of several packages by using imports instead of uses when building packages.
By default the compiler tries first to find a package (the corresponding file is libname.bim) then, if this fails, it searches for a module (which file name is libname.dso). It is possible to indicate the type of library to look for by appending either ".bim" or ".dso" to the name (then the compiler does not try the alternative in case of failure). A package may also be specified by an extended file name (see Section File names and input/output drivers) including the IO driver in order to disable the automatic search (i.e. "a.bim" searches the file a.bim in the library path but ":a.bim" takes the file a.bim from the current directory).
For example,
uses 'mmsystem','mmxprs.dso','mypkg.bim' uses ':/tmp/otherpkg.bim'
Both packages and modules are searched in a list of possible locations initialized by means of environment variables. Upon startup, Mosel uses as the default for this list the value of the environment variable MOSEL_DSO completed by the subdirectory dso in the Mosel installation directory. This directory is taken from one of the environment variables MOSEL, XPRESSDIR or XPRESS (note that Mosel console still works even if none of these variables is defined). The variable MOSEL_DSO is expected to be a list of paths conforming to the operating system conventions: for a Unix system the path separator is ':' (e.g. "/opt/Mosel/dso:/tmp") and it is ';' under Win32 (e.g. "E:\Mosel\Dso;C:\Temp"). The search path for modules and packages may also be inspected and modified from the Mosel Libraries (see functions XPRMgetdsopath and XPRMsetdsopath in the Mosel Libraries Reference Manual).
Directive imports
The general form of an imports statement is:
| imports pkgname1 [, pkgname2 ...][;] |
This clause is a special version of the uses directive that can only be used in packages: it asks the compiler to load the listed packages, import the symbols they define and incorporate the corresponding bim file. As a consequence, the generated package provides the functionality of the packages it imports.
For example,
imports 'mypkg'
Directive options
The compiler options may be used to modify the default behaviour of the compiler. The general form of an options statement is:
| options optname1 [, optname2 ...] |
The supported options are:
- explterm: asks the compiler to expect explicit expression termination (see Section Separation of instructions, line breaking)
- noimplicit: disables the implicit declarations (see Section About implicit declarations)
- keepassert: assertions (cf. assert) are compiled only in debug mode. With this option assertions are preserved regardless of the compilation mode.
For example,
options noimplicit,explterm
Directive version
In addition to the model/package name, a file version number may be specified using this directive: a version number consists in 1, 2 or 3 integers between 0 and 999 separated by the character '.'.
| version major [. minor [. release ]] |
For example,
version 1.2
The file version is stored in the BIM file and can be displayed from the Mosel console (command list) or retrieved using the Mosel Libraries (see function XPRMgetmodprop in the Mosel Libraries Reference Manual).
The parameters block
A model parameter is a symbol, the value of which can be set just before running the model (optional parameter of the 'run' command of the command line interpreter). The general form of the parameters block is:
| parameters ident1 = Expression1 [ ident2 = Expression2 ...] end-parameters |
where each identifier identi is the name of a parameter and the corresponding expression Expressioni its default value. This value is assigned to the parameter if no explicit value is provided at the start of the execution of the program (e.g. as a parameter of the 'run' command). Note that the type (integer, real, text string or Boolean) of a parameter is implied by its default value. Model parameters are manipulated as constants in the rest of the source file (it is not possible to alter their original value).
parameters size=12 ! Integer parameter R=12.67 ! Real parameter F="myfile" ! Text string parameter B=true ! Boolean parameter end-parameters
In addition to model parameters, Mosel and some modules provide control parameters : they can be used to give information on the system (e.g. success of an I/O operation) or control its behaviour (e.g. select output format of real numbers). These parameters can be accessed and modified using the routines getparam and setparam. Refer to the documentation of these functions for a complete listing of available Mosel parameters. The documentation of the modules include the description of the parameters they publish.
Source file preprocessing
Source file inclusion
A Mosel program may be split into several source files by means of file inclusion. The 'include' instruction performs this task:
| include filename |
where filename is the name of the file to be included. This file name may contain environment variable references using the notation ${varname} (e.g. '${MOSEL}/examples/mymodel') that are expanded to generate the actual name. The 'include' instruction is replaced at compile time by the contents of the file filename.
Assuming the file a.mos contains:
model "Example for file inclusion"
writeln('From the main file')
include "b.mos"
end-model
And the file b.mos:
writeln('From an included file')
Due to the inclusion of b.mos, the file a.mos is equivalent to:
model "Example for file inclusion"
writeln('From the main file')
writeln('From an included file')
end-model
Note that file inclusion cannot be used inside blocks of instructions or before the body of the program (as a consequence, a file included cannot contain any of the following statements: uses, options or parameters).
Line control directives
In some cases it may be useful to process a Mosel source through an external preprocessor before compilation. For instance this may enable the use of facilities not supported by the Mosel compiler like macros, unrestricted file inclusion or conditional compilation. In order to generate meaningful error messages, the Mosel compiler supports line control directives: these directives are inserted by preprocessors (e.g. cpp or m4) to indicate the original location (file name and line number) of generated text.
| #[line] linenum [filename] |
To be properly interpreted, a line control directive must be the only statement of the line. Malformed directives and text following valid directives are silently ignored.
The declaration block
The role of the declaration block is to give a name, a type, and a structure to the entities that the processing part of the program/model will use. The type of a value defines its domain (for instance integer or real) and its structure, how it is organized, stored (for instance a reference to a single value or an ordered collection in the form of an array). The declaration block is composed of a list of declaration statements enclosed between the instructions declarations and end-declarations.
| declarations Declare_stat [ Declare_stat ...] end-declarations |
Several declaration blocks may appear in a single source file but a symbol introduced in a given block cannot be used before that block. Once a name has been assigned to an entity, it cannot be reused for anything else.
Elementary types
Elementary objects are used to build up more complex data structures like sets or arrays. It is, of course, possible to declare an entity as a reference to a value of one of these elementary types. Such a declaration looks as follows:
| ident1 [, ident2 ...]: type_name |
where type_name is the type of the objects to create. Each of the identifiers identi is then declared as a reference to a value of the given type. The type name may be either a basic type (integer, real, string, boolean), an MP type (mpvar, linctr), an external type or a user defined type (see section User defined types). MP types are related to Mathematical Programming and allow declaration of decision variables and linear constraints. Note that the linear constraint objects can also be used to store linear expressions. External types are defined by modules (the documentation of each module describes how to use the type(s) it implements).
declarations i,j: integer str: string x,y,z: mpvar end-declarations
Basic types
- integer: an integer value between -214783648 and 2147483647
- real: a real value between -1.7e+308 and 1.7e+308.
- string: some text.
- boolean: the result of a Boolean (logical) expression. The value of a Boolean entity is either the symbol true or the symbol false.
After its declaration, each entity receives an initial value of 0, an empty string, or false depending on its type.
MP types
Two special types are provided for mathematical programming.
Sets
Sets are used to group an unordered collection of elements of a given type. Set elements are unique: if an element is added several times it is only contained once in the set. Declaring a set consists of defining the type of elements to be collected.
The general form of a set declaration is:
| ident1 [, ident2 ...] : set of type_name |
where type_name is one of the elementary types. Each of the identifiers identi is then declared as a set of the given type.
A particular set type is also available that should be preferred to the general form wherever possible because of its better efficiency: the range set is an ordered collection of consecutive integers in a given interval. The declaration of a range set is achieved by:
| ident1 [, ident2 ...] : range [set of integer] |
Each of the identifiers identi is then declared as a range set of integers. Every newly created set is empty.
declarations s1: set of string r1: range end-declarations
Lists
Lists are used to group a collection of elements of a given type. An element can be stored several times in a list and order of the elements is specified by construction. Declaring a list consists of defining the type of elements to be collected.
The general form of a list declaration is:
| ident1 [, ident2 ...] : list of type_name |
where type_name is one of the elementary types. Each of the identifiers identi is then declared as a list of the given type.
Every newly created list is empty.
declarations l1: list of string l2: list of real end-declarations
Arrays
An array is a collection of labelled objects of a given type. A label is defined by a list of indices taking their values in domains characterized by sets: the indexing sets. An array may be either of fixed size or dynamic. For fixed size arrays, the size (i.e. the total number of objects it contains, or cells) is known when it is declared. All the required cells (one for each object) are created and initialized immediately. Dynamic arrays are created empty. The cells are created explicitly (cf. procedure create) or when they are assigned a value (cf. Section Assignment) and the array may then grow `on demand'. It is also possible to delete some or all cells of a dynamic array using the procedure delcell. The value of a cell that has not been created is the default initial value of the type of the array. The general form of an array declaration is:
| ident1 [, ident2 ...] : [dynamic] array(list_of_sets) of type_name |
where list_of_sets is a list of set declarations/expressions separated by commas and type_name is one of the elementary types. Each of the identifiers identi is then declared as an array of the given type and indexed by the given sets. In the list of indexing sets, a set declaration can be anonymous (i.e. rs:set of real can be replaced by set of real if no reference to rs is required) or shortened to the type of the set (i.e. set of real can be replaced by real in that context).
declarations
e: set of string
t1:array ( e, rs:set of real, range, integer ) of real
t2:array ( {"i1","i2"}, 1..3 ) of integer
end-declarations
An array is of fixed size if all of its indexing sets are of fixed size (i.e. they are either constant or finalized (cf. procedure finalize)). If the qualifier dynamic is used, the array is dynamic and created empty. Otherwise (at least one indexing set is not constant), the array is created with as many cells as possible (i.e., the array is empty if one of the indexing sets is not initialized) and may grow if necessary. Such an array is not the same as a dynamic array even if it is created empty: Mosel may use a dedicated internal representation through which the creation of a single cell (via an assignment for instance) may induce the creation of a row of adjacent cells. The following example shows the different behaviour of an array that is simply declared with unknown index set (a) and an explicit dynamic array (b).
declarations r: range a: array(r) of integer ! a is created empty b: dynamic array(r) of integer ! b is created empty end-declarations r:=1..3 finalize(r) ! now the index set is known and constant a(2):=1 ! here entries a(1) and a(3) are also created b(2):=1 ! b(2) is the only entry of b
Note that once a set is employed as an indexing set, Mosel makes sure that its size is never reduced in order to guarantee that no entry of any array becomes inaccessible. Such a set is called fixed.
Special case of dynamic arrays of a type not supporting assignment
Certain types do not have assignment operators: for instance, writing x:=1 is a syntax error if x is of type mpvar. If an array of such a type is defined as dynamic or the size of at least one of its indexing sets is unknown at declaration time (i.e. empty set), the corresponding cells are not created. In that case, it is required to create each of the relevant entries of the array by using the procedure create since entries cannot be defined by assignment.
Records
A record is a finite collection of objects of any type. Each component of a record is called a field and is characterized by its name (an identifier) and its type. The general form of a record declaration is:
| ident1 [, ident2 ...] : record field1 [, field2 ...]: type_name [...] end-record |
where fieldi are the identifiers of the fields of the record and type_name one of the elementary types. Each of the identifiers identi is then declared as a record including the listed fields.
Example:
declarations
r1: record
i,j:integer
r:real
end-record
end-declarations
Each record declaration is considered unique by the compiler. In the following example, although r1 and r2 have the same definitions, they are not of the same type (but r3 is of course of the type of r2):
declarations
r1: record
i,j:integer
end-record
r2,r3: record
i,j:integer
end-record
end-declarations
Constants
A constant is an identifier for which the value is known at declaration time and that will never be modified. The general form of a constant declaration is:
| identifier = Expression |
where identifier is the name of the constant and Expression its initial and only value. The expression must be of one of the basic types, a set or a list of one of these types.
Example:
declarations
STR='my const string'
I1=12
R=1..10 ! constant range
S={2.3,5.6,7.01} ! constant set
L=[2,4,6] ! constant list
end-declarations
The compiler supports two kinds of constants: a compile time constant is a constant which value can be computed by the compiler. A run time constant will be known only when the model is run.
Example:
parameters P=0 end-parameters declarations I=1/3 ! compile time constant J=P*2 ! run time constant end-declarations
User defined types
Naming new types
A new type may be defined by associating an identifier to a type declaration. The general form of a type definition is:
| identifier = Type_def |
where Type_def is a type (elementary, set, list, array or record) to be associated to the symbol identifier. After such a definition, the new type may be used wherever a type name is required.
Example:
declarations entier=integer setint=set of entier i:entier ! <=> i:integer s:setint ! <=> s:set of integer end-declarations
Note that only compile time constant or globally defined sets are allowed as indices to array types:
declarations ar1=array(1..10) of integer ! OK ar2=array(range) of integer ! incorrect R:range ar3=array(R) of integer ! OK end-declarations
Combining types
Thanks to user defined types one can create complex data structures by combining structures offered by the language. For instance an array of sets may be defined as follows:
declarations typset=set of integer a1:array(1..10) of typset end-declarations
In order to simplify the description of complex data structures, the Mosel compiler can generate automatically the intermediate user types. Using this property, the example above can be written as follows (both arrays a1 and a2 are of the same type):
declarations a2:array(1..10) of set of integer end-declarations
Expressions
Expressions are, together with the keywords, the major building blocks of a language. This section summarizes the different basic operators and connectors used to build expressions.
Introduction
Expressions are constructed using constants, operators and identifiers (of objects or functions). If an identifier appears in an expression its value is the value referenced by this identifier. In the case of a set, a list, an array or a record, it is the whole structure. To access a single cell of an array, it is required to 'dereference' this array. The dereferencing of an array is denoted as follows:
| array_ident (Exp1 [, Exp2 ...]) |
where array_ident is the name of the array and Expi an expression of the type of the ith indexing set of the array. The type of such an expression is the type of the array and its value the value stored in the array with the label 'Exp1 [, Exp2 ...]'. In order to access the cell of an array of arrays, the list of indices for the second array has to be appended to the list of indices of the first array. For instance, the array a:array(1..10) of array(1..10) of integer can be dereferenced with a(1,2).
Similarly, to access the field of a record, it is required to 'dereference' this record. The dereferencing of a record is denoted as follows:
| record_ident.field_ident |
where record_ident is the name of the record and field_ident the name of the required field.
Dereferencing arrays of records is achieved by combining the syntax for the two structures. For instance a(1).b
A function call is denoted as follows:
| function_ident or function_ident (Exp1 [, Exp2 ...]) |
where function_ident is the name of the function and Expi the ith parameter required by this function. The first form is for a function requiring no parameter.
The special function if allows one to make a selection among expressions. Its syntax is the following:
| if (Bool_expr, Exp1, Exp2) |
which evaluates to Exp1 if Bool_expr is true or Exp2 otherwise. The type of this expression is the type of Exp1 and Exp2 which must be of the same type.
The Mosel compiler operates automatic conversions to the type required by a given operator in the following cases:
- in the dereference list of an array:
integer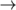 real;
real;
- in a function or procedure parameter list:
integer real, linctr;
real linctr;
mpvar linctr;
- anywhere else:
integer real, string, linctr;
real string, linctr;
mpvar linctr;
boolean string.
It is possible to force a basic type conversion using the type name as a function (i.e. integer, real, string, boolean). In the case of string, the result is the textual representation of the converted expression. In the case of boolean, for numerical values, the result is true if the value is nonzero and for strings the result is true if the string is the word `true'. Note that explicit conversions are not defined for MP types, and structured types .(e.g. linctr(x) is a syntax error).
! Assuming A=3.5, B=2
integer(A+B) ! = 5
string(A-B) ! = "1.5"
real(integer(A+B)) ! = 5.5 (because the compiler simplifies
the expression)
Parentheses may be used to modify the predefined evaluation order of the operators or simply to group subexpressions.
Aggregate operators
An operator is said to be aggregate when it is associated to a list of indices for each of which a set or list of values is defined. This operator is then applied to its operands for each possible tuple of values (e.g. the summation operator sum is an aggregate operator). The general form of an aggregate operator is:
| Aggregate_ident (Iterator1 [, Iterator2 ...]) Expression |
where the Aggregate_ident is the name of the operator and Expression an expression compatible with this operator (see below for the different available operators). The type of the result of such an aggregate expression is the type of Expression.
An iterator is one of the following constructs:
| SetList_expr or ident1 [, ident2 ...] in SetList_expr [| Bool_expr] or ident = Expression [| Bool_expr] |
The first form gives the list of the values to be taken without specifying an index name. With the second form, the indices named identi take successively all values of the set or list defined by SetList_expr. With the third form, the index ident is assigned a single value (which must be a scalar). For the last two cases, the scope of the created identifier is limited to the scope of the operator (i.e. it exists only for the following iterators and for the operand of the aggregate operator). Moreover, an optional condition can be stated by means of Bool_expr which can be used as a filter to select the relevant elements of the domain of the index. It is important to note that this condition is evaluated as early as possible. As a consequence, a Boolean expression that does not depend on any of the defined indices in the considered iterator list is evaluated only once, namely before the aggregate operator itself and not for each possible tuple of indices.
The Mosel compiler performs loop optimization when function exists is used as the first factors of the condition in order to enumerate only those tuples of indices that correspond to actual cells in the array instead of all possible tuples. To be effective, this optimization requires that sets used to declare the array on which the exist condition applies must be named and the same sets must be used to define the index domains. Moreover, the maximum speedup is obtained when order of indices is respected and all indices are defined in the same aggregate operator.
An index is considered to be a constant: it is not possible to change explicitly the value of a named index (using an assignment for instance).
Arithmetic expressions
Numerical constants can be written using the common scientific notation. Arithmetic expressions are naturally expressed by means of the usual operators (+, -, *, / division, unary -, unary +, ^ raise to the power). For integer values, the operators mod (remainder of division) and div (integral division) are also defined. Note that mpvar objects are handled like real values in expression.
The sum (summation) aggregate operators is defined on integers, real and mpvar. The aggregate operators prod (product), min (minimum) and max (maximum) can be used on integer and real values.
x*5.5+(2+z)^4+cos(12.4) sum(i in 1..10) (min(j in s) t(i)*(a(j) mod 2))
String expressions
Constant strings of characters must be quoted with single (') or double quote ("). Strings enclosed in double quotes may contain C-like escape sequences introduced by the 'backslash' character (\a \b \f \n \r \t \v).
Each sequence is replaced by the corresponding control character (e.g. \n is the `new line' command) or, if no control character exists, by the second character of the sequence itself (e.g. \\ is replaced by '\').
The escape sequences are not interpreted if they are contained in strings that are enclosed in single quotes.
Example:
| 'c:\ddd1\ddd2\ddd3' is understood as c:\ddd1\ddd2\ddd3 "c:\ddd1\ddd2\ddd3" is understood as c:ddd1ddd2ddd3 |
There are two basic operators for strings: the concatenation, written '+' and the difference, written '-'.
"a1b2c3d5"+"e6" ! = "a1b2c3d5e6" 'a1b2c3d5'-"3d5" ! = "a1b2c"
Set expressions
Constant sets are described using one of the following constructs:
| {[ Exp1 [, Exp2 ...]]} or Integer_exp1 .. Integer_exp2 |
The first form enumerates all the values contained in the set and the second form, restricted to sets of integers, gives an interval of integer values. This form implicitly defines a range set.
The basic operators on sets are the union written +, the difference written - and the intersection written *.
The aggregate operators union and inter can also be used to build up set expressions.
{1,2,3}+{4,5,6}-(5..8)*{6,10} ! = {1,2,3,4,5}
{'a','b','c'}*{'b','c','d'} ! = {'b','c'}
union(i in 1..4|i<>2) {i*3} ! = {3,9,12}
If several range sets are combined in the same expression, the result is either a range or a set of integers depending on the continuity of the produced domain. If range sets and sets of integers of more than one element are combined in an expression, the result is a set of integers. It is however possible to convert a set of integers to a range by using the notation range(setexpr) where setexpr is a set expression which result is either a set of integers or a range.
List expressions
A constant list consist in a list of expressions enclosed in square brackets:
| [[ Exp1 [, Exp2 ...]]] |
There are two basic operators for lists: the concatenation, written '+' and the difference, written '-'. The aggregate operator sum can also be used to build up list expressions.
[1,2,3]+[1,2,3] ! = [1,2,3,1,2,3] [1,2,3,4]-[3,4] ! = [1,2] sum(i in 1..3) [i*3] ! = [3,6,9]
Boolean expressions
A Boolean expression is an expression whose result is either true or false. The traditional comparators are defined on integer and real values: <, <=, =, <> (not equal), >=, >.
These operators are also defined for string expressions. In that case, the order is defined by the ISO-8859-1 character set (i.e. roughly: punctuation < digits < capitals < lower case letters < accented letters).
With sets, the comparators <= (`is subset of'), >= (`is superset of'), = (`equality of contents') and <> (`difference of contents') are defined. These comparators must be used with two sets of the same type. Moreover, the operator `expr in Set_expr' is true if the expression expr is contained in the set Set_expr. The opposite, the operator not in is also defined.
With lists, the comparators = (`equality of contents') and <> (`difference of contents') are defined. These comparators must be used with two lists of the same type.
To combine Boolean expressions, the operators and (logical and) and or (logical or) as well as the unary operator not (logical negation) can be used. The evaluation of an arithmetic expression stops as soon as its value is known.
The aggregate operators and and or are the natural extension of their binary counterparts.
3<=x and y>=45 or t<>r and not r in {1..10}
and(i in 1..10) 3<=x(i)
Linear constraint expressions
Linear constraints are built up using linear expressions on the decision variables (type mpvar).
The different forms of constraints are:
| Linear_expr or Linear_expr1 Ctr_cmp Linear_expr2 or Linear_expr SOS_type or mpvar_ref mpvar_type1 or mpvar_ref mpvar_type2 Arith_expr |
In the case of the first form, the constraint is unconstrained and is just a linear expression. For the second form, the valid comparators are <=, >=, =. The third form is used to declare special ordered sets. The types are then is_sos1 and is_sos2. The coefficients of the variables in the linear expression are used as weights for the SOS (as a consequence, a 0-weighted variable cannot be represented this way, procedure makesos1 or makesos2 has to be used instead). The last two types are used to set up special types for decision variables. The first series does not require any extra information: is_continuous, is_integer, is_binary, is_free. The second series of types is associated with a threshold value stated by an arithmetic expressions: is_partint for partial integer, the value indicates the limit up to which the variable must be integer, above which it is continuous. For is_semcont (semi-continuous) and is_semint (semi-continuous integer) the value gives the semi-continuous limit of the variable (that is, the lower bound on the part of its domain that is continuous or consecutive integers respectively). Note that these constraints on single variables are also considered as common linear constraints.
3*y+sum(i in 1..10) x(i)*i >= z-t
t is_integer ! Define an integer variable
t >= 7 ! Lower bound on t: t=7,8,...
sum(i in 1..10) i*x(i) is_sos1 ! SOS1 {x(1),x(2),...} with
! weights 1,2,...
y is_partint 5 ! y=0 or y=5,6,...
y <= 20 ! Upper bound on y: y=0 or y=5,6,...,20
Internally all linear constraints are stored in the same form: a linear expression (including a constant term) and a constraint type (the right hand side is always 0). This means, the constraint expression 3*x>=5*y-10 is internally represented by: 3*x-5*y+10 and the type `greater than or equal to'. When a reference to a linear constraint appears in an expression, its value is the linear expression it contains. For example, if the identifier ctl refers to the linear constraint 3*x>=5*y-10, the expression z-x+ctl is equal to: z-2*x-5*y+10.
Note that the value of a unary constraint of the type x is_type threshold is x-threshold.
Statements
Four types of statements are supported by the Mosel language. The simple statements can be seen as elementary operations. The initialization block is used to load data from a file or save data to a file. Selection statements allow one to choose between different sets of statements depending on conditions. Finally, the loop statements are used to repeat operations.
Each of these constructs is considered as a single statement. A list of statements is a succession of statements. No particular statement separator is required between statements except if a statement terminates by an expression. In that case, the expression must be finished by either a line break or the symbol ';'.
Simple statements
Assignment
An assignment consists in changing the value associated to an identifier. The general form of an assignment is:
| ident_ref := Expression or ident_ref += Expression or ident_ref -= Expression |
where ident_ref is a reference to a value (i.e. an identifier or an array/record dereference) and Expression is an expression of a compatible type with ident_ref. The direct assignment, denoted := replaces the value associated with ident_ref by the value of the expression. The additive assignment, denoted +=, and the subtractive assignment, denoted -=, are basically combinations of a direct assignment with an addition or a subtraction. They require an expression of a type that supports these operators (for instance it is not possible to use additive assignment with Boolean objects).
The additive and subtractive assignments have a special meaning with linear constraints in the sense that they preserve the constraint type of the assigned identifier: normally a constraint used in an expression has the value of the linear expression it contains, the constraint type is ignored.
c:= 3*x+y >= 5 c+= y ! Implies c is 3*x+2*y-5 >= 0 c:= 3*x+y >= 5 c:= c + y ! Implies c is 3*x+2*y-5 (c becomes unconstrained)
Assignment of structured types
The direct assignment := can also be used with sets, lists, arrays and records under certain conditions. For sets and lists, reference and value must be of the same type, the system performing no conversion on structures. For instance it is not possible to assign a set of integers to a set of reals although assigning an integer value to a real object is valid.
When assigning records, reference and value must be of the same type and this type must be assignment compatible: two records having identical definitions are not considered to be the same type by the compiler. In most cases it will be necessary to employ a user type to declare the objects. A record is assignment compatible if all the fields it includes can be assigned a value. For instance a record including a decision variable (type mpvar) cannot be used in an assignment: copying a value of such a type has to be performed one field at a time skiping those fields that cannot be assigned.
Two arrays can be used in an assignment if they have strictly the same definition and are assignment compatible (i.e. their type supports assignment). Note that in a few cases arrays sharing the same definition cannot be assigned because their internal representations differ like in the following example:
declarations a:array(R:range) of integer ! 'a' is dynamic end-declarations R:=1..10 finalise(R) declarations b:array(R) of integer ! 'b' is static end-declarations a:=b ! fails at run time
About implicit declarations
Each symbol should be declared before being used. However, an implicit declaration is issued when a new symbol is assigned a value the type of which is unambiguous.
! Assuming A,S,SE are unknown symbols
A:= 1 ! A is automatically defined
! as an integer reference
S:={1,2,3} ! S is automatically defined
! as a set of integers
SE:={} ! This produces a parser error as
! the type of SE is unknown
In the case of arrays, the implicit declaration should be avoided or used with particular care as Mosel tries to deduce the indexing sets from the context and decides automatically whether the created array must be dynamic. The result is not necessarily what is expected.
A(1):=1 ! Implies: A:array(1..1) of integer
A(t):=2.5 ! Assuming "t in 1..10|f(t) > 0"
! implies: A:dynamic array(range) of real
The option noimplicit disables implicit declarations.
Inline initialization
Using inline initialization it is possible to assign several cells of an array in a single statement. The general form of an inline initialization is:
| ident_ref ::[ Exp1 [, Exp2 ...] ] or ident_ref ::(Ind1 [, Ind2 ...] )[ Exp1 [, Exp2 ...] ] |
where ident_ref is the object to initialize (array, set or list) and Expi are expressions of a compatible type with ident_ref. The first form of this statement may be used with lists, sets and arrays indiced by ranges: the list of expressions is used to initialize the object. In the case of lists and sets this operation is similar to a direct assignment, with an array, the first index of each dimension is the lower bound of the indexing range or 1 if the range is empty.
The second form is used to initialize regions of arrays or arrays indiced by general sets: each Indi expression indicates the index or list of indices for the corresponding dimension. An index list can be a constant, a list of constants (e.g. ['a','b','c']) or a constant range (e.g. 1..10) but all values must be known at compile time.
declarations
T:array(1..10) of integer
U:array(1..9,{'a','b','c'}) of integer
end-declarations
T::[2,4,6,8] ! <=> T(1):=2; T(2):=4;...
T::(2..5)[7,8,9,19] ! <=> T(2):=7; T(3):=8;...
U::([1,3,6],'b')[1,2,3]! <=> U(1,'b'):=1; U(3,'b'):=2;...
Linear constraint expression
A linear constraint expression can be assigned to an identifier but can also be stated on its own. In that case, the constraint is said to be anonymous and is added to the set of already defined constraints. The difference from a named constraint is that it is not possible to refer to an anonymous constraint again, for instance to modify it.
10<=x; x<=20 x is_integer
Procedure call
Not all required actions are coded in a given source file. The language comes with a set of predefined procedures that perform specific actions (like displaying a message). It is also possible to import procedures from external locations by using modules or packages (cf. Section The compiler directives).
The general form of a procedure call is:
| procedure_ident procedure_ident (Exp1 [, Exp2 ...]) |
where procedure_ident is the name of the procedure and, if required, Expi is the ith parameter for the call. Refer to Chapter Predefined functions and procedures of this manual for a comprehensive listing of the predefined procedures.The modules documentation should also be consulted for explanations about the procedures provided by each module.
| writeln("hello!") ! Displays the message: hello! |
Initialization block
The initialization block may be used to initialize objects (scalars, arrays, lists or sets) of basic type from text files or to save the values of such objects to text files. Scalars and arrays of external types supporting this feature may also be initialized using this facility.
The first form of an initialization block is used to initialize data from a file:
| initializations from Filename ident1 [ as Label1] or [identT11, identT12 [ ,IdentT13 ...]] as LabelT1 [ ident2 [ as Label2] or [identT21, identT22 [ ,IdentT23 ...]] as LabelT2 ...] end-initializations |
where Filename, a string expression, is the name of the file to read, identi any object identifier and identTij an array identifier. Each identifier is automatically associated to a label: by default this label is the identifier itself but a different name may be specified explicitly using a string expression Labeli. When an initialization block is executed, the given file is opened and the requested labels are searched for in this file to initialize the corresponding objects. Several arrays may be initialized with a single record. In this case they must be all indexed by the same sets and the label is obligatory. After the execution of an initializations from block, the control parameter nbread reports the number of items actually read in. Moreover, if control parameter readcnt is set to true before the execution of the block, counting is also achieved at the label level: the number of items actually read in for each label may be obtained using function getreadcnt.
An initialization file must contain one or several records of the following form:
| Label: value |
where Label is a text string and value either a constant of a basic type (integer, real, string or boolean) or a collection of values separated by spaces and enclosed in square brackets. Collections of values are used to initialize lists, sets records or arrays — if such a record is requested for a scalar, then the first value of the collection is selected. When used for arrays, indices enclosed in round brackets may be inserted in the list of values to specify a location in the corresponding array.
Note also that:
- no particular formatting is required: spaces, tabulations, and line breaks are just normal separators
- the special value '*' implies a no-operation (i.e. the corresponding entity is not initialized)
- single line comments are supported (i.e. starting with '!' and terminated by the end of the line)
- Boolean constants are either the identifiers false (FALSE) and true (TRUE) or the numerical constants 0 and 1
- all text strings (including the labels) may be quoted using either single or double quotes. In the latter case, escape sequences are interpreted (i.e. use of '\').
The second form of an initialization block is used to save data to a file:
| initializations to Filename ident1 [as Label1] or [identT11, identT12 [ ,IdentT13 ...]] as LabelT1 [ ident2 [ as Label2] or [identT21, identT22 [ ,IdentT23 ...]] as LabelT2 ...] end-initializations |
When this second form is executed, the value of all provided labels is updated with the current value of the corresponding identifier—A copy of the original file is saved prior to the update (i.e. the original version of fname can be found in fname ˜).— in the given file. If a label cannot be found, a new record is appended to the end of the file and the file is created if it does not yet exist.
For example, assuming the file a.dat contains:
! Example of the use of initialization blocks t:[ (1 un) [10 11] (2 deux) [* 22] (3 trois) [30 33]] t2:[ 10 (4) 30 40 ] 'nb used': 0
consider the following program:
model "Example initblk"
declarations
nb_used:integer
s: set of string
ta,tb: array(1..3,s) of real
t2: array(1..5) of integer
end-declarations
initializations from 'a.dat'
[ta,tb] as 't' ! ta=[(1,'un',10),(3,'trois',30)]
! tb=[(1,'un',11),(2,'deux',22),(3,'trois',33)]
t2 ! t2=[10,0,0,30,40]
nb_used as "nb used" ! nb_used=0
end-initializations
nb_used+=1
ta(2,"quatre"):=1000
initializations to 'a.dat'
[ta,tb] as 't'
nb_used as "nb used"
s
end-initializations
end-model
After the execution of this model, the data file contains:
! Example of the use of initialization blocks t:[(1 'un') [10 11] (2 'deux') [* 22] (2 'quatre') [1000 *] (3 'trois') [30 33]] t2:[ 10 (4) 30 40 ] 'nb used': 1 's': ['un' 'deux' 'trois' 'quatre']
In case of error (e.g. file not found, corrupted data format) during the processing of an initialization block, the execution of the model is interrupted. However if the value of control parameter ioctrl is true, executions continues. It is up to the user to verify whether data has been properly transfered by checking the value of control parameter iostatus.
Selections
If statement
The general form of the if statement is:
| if Bool_exp_1 then Statement_list_1 [ elif Bool_exp_2 then Statement_list_2 ...] [ else Statement_list_E ] end-if |
The selection is executed as follows: if Bool_exp_1 is true then Statement_list_1 is executed and the process continues after the end-if instruction. Otherwise, if there are elif statements, they are executed in the same manner as the if instruction itself. If, all boolean expressions evaluated are false and there is an else instruction, then Statement_list_E are executed; otherwise no statement is executed and the process continues after the end-if keyword.
if c=1
then writeln('c=1')
elif c=2
then writeln('c=2')
else writeln('c<>1 and c<>2')
end-if
Case statement
The general form of the case statement is:
| case Expression_0 of Expression_1: Statement_1 or Expression_1: do Statement_list_1 end-do [ Expression_2: Statement_2 or Expression_2: do Statement_list_2 end-do ...] [ else Statement_list_E ] end-case |
The selection is executed as follows: Expression_0 is evaluated and compared sequentially with each expression of the list Expression_i until a match is found. Then the statement Statement_i (resp. list of statements Statement_list_i) corresponding to the matching expression is executed and the execution continues after the end-case instruction. If no matching is found and an else statement is present, the list of statements Statement_list_E is executed, otherwise the execution continues after the end-case instruction. Note that, each of the expression lists Expression_i can be either a scalar, a set or a list of expressions separated by commas. In the last two cases, the matching succeeds if the expression Expression_0 corresponds to an element of the set or an entry of the list.
case c of
1 : writeln('c=1')
2..5 : writeln('c in 2..5')
6,8,10: writeln('c in {6,8,10}')
else writeln('c in {7,9} or c >10 or c <1')
end-case
Loops
Forall loop
The general form of the forall statement is:
| forall (Iterator_list) Statement
or forall (Iterator_list) do Statement_list end-do |
The statement Statement (resp. list of statements Statement_list) is repeated for each possible index tuple generated by the iterator list (cf. Section Aggregate operators).
forall (i in 1..10, j in 1..10 | i<>j) do
write(' (' , i, ',' , j, ')')
if isodd(i*j) then s+={i*j}
end-if
end-do
While loop
The general form of the while statement is:
| while (Bool_expr) Statement or while (Bool_expr) do Statement_list end-do |
The statement Statement (resp. list of statements Statement_list) is repeated as long as the condition Bool_expr is true. If the condition is false at the first evaluation, the while statement is entirely skipped.
i:=1
while(i<=10) do
write(' ',i)
if isodd(i) then s+={i}
end-if
i+=1
end-do
Repeat loop
The general form of the repeat statement is:
| repeat Statement1 [ Statement2 ...] until Bool_expr |
The list of statements enclosed in the instructions repeat and until is repeated until the condition Bool_expr is true. As opposed to the while loop, the statement(s) is (are) executed at least once.
i:=1
repeat
write(' ',i)
if isodd(i) then s+={i}
end-if
i+=1
until i>10
break and next statements
The statements break and next are respectively used to interrupt and jump to the next iteration of a loop. The general form of the break and next statements is:
| break [n] or next [n] |
where n is an optional integer constant: n-1 nested loops are stopped before applying the operation.
! in this example only the loop controls are shown repeat ! 1: Loop L1 forall (i in S) do ! 2: Loop L2 while (C3) do ! 3: Loop L3 break 3 ! 4: Stop the 3 loops and continue after line 11 next ! 5: Go to next iteration of L3 (line 3) next 2 ! 6: Stop L3 and go to next 'i' (line 2) end-do ! 7: End of L3 next 2 ! 8: Stop L2, go to next iteration of L1 (line 11) break ! 9: Stop L2 and continue after line 10 end-do !10: End of L2 until C1 !11: End of L1
Procedures and functions
It is possible to group sets of statements and declarations in the form of subroutines that, once defined, can be called several times during the execution of the model. There are two kinds of subroutines in Mosel, procedures and functions. Procedures are used in the place of statements (e.g. writeln("Hi!")) and functions as part of expressions (because a value is returned, e.g. round(12.3)). Procedures and functions may both receive arguments, define local data and call themselves recursively.
Definition
Defining a subroutine consists of describing its external properties (i.e. its name and arguments) and the actions to be performed when it is executed (i.e. the statements to perform). The general form of a procedure definition is:
| procedure name_proc [(list_of_parms)] Proc_body end-procedure |
where name_proc is the name of the procedure and list_of_parms its list of formal parameters (if any). This list is composed of symbol declarations (cf. Section The declaration block) separated by commas. The only difference from usual declarations is that no constants or expressions are allowed, including in the indexing list of an array (for instance A=12 or t1:array(1..4) of real are not valid parameter declarations). The body of the procedure is the usual list of statements and declaration blocks except that no procedure or function definition can be included.
procedure myproc
writeln("In myproc")
end-procedure
procedure withparams(a:array(r:range) of real, i,j:integer)
writeln("I received: i=",i," j=",j)
forall(n in r) writeln("a(",n,")=",a(n))
end-procedure
declarations
mytab:array(1..10) of real
end-declarations
myproc ! Call myproc
withparams(mytab,23,67) ! Call withparams
The definition of a function is very similar to the one of a procedure:
| function name_func [(List_of_params)]: Type Func_body end-function |
The only difference with a procedure is that the function type must be specified: it can be any type name except mpvar. Inside the body of a function, a special variable of the type of the function is automatically defined: returned. This variable is used as the return value of the function, it must therefore be assigned a value during the execution of the function.
function multiply_by_3(i:integer):integer
returned:=i*3
end-function
writeln("3*12=", multiply_by_3(12)) ! Call the function
Formal parameters: passing convention
Formal Parameters of basic types are passed by value and all other types are passed by reference. In practice, when a parameter is passed by value, the subroutine receives a copy of the information so, if the subroutine modifies this parameter, the effective parameter remains unchanged. But if a parameter is passed by reference, the subroutine receives the parameter itself. As a consequence, if the parameter is modified during the process of the subroutine, the effective parameter is also affected.
procedure alter(s:set of integer,i:integer)
i+=1
s+={i}
end-procedure
gs:={1}
gi:=5
alter(gs,gi)
writeln(gs," ",gi) ! Displays: {1,6} 5
Local declarations
Several declaration blocks may be used in a subroutine and all identifiers declared are local to this subroutine. This means that all of these symbols exist only in the scope of the subroutine (i.e. between the declaration and the end-procedure or end-function statement) and all of the resource they use is released once the subroutine terminates its execution unless they are referenced outside of the routine (e.g. member of a set defined globally). As a consequence, active constraints (linctr that are not just linear expressions) declared inside a subroutine and the variables they employ are still effective after the termination of the subroutine (because they are part of the current problem) even if the symbols used to name the related objects are not defined any more. Note also that a local declaration may hide a global symbol.
declarations ! Global definition
i,j:integer
end-declarations
procedure myproc
declarations
i:string ! This declaration hides the global symbol
end-declarations
i:="a string" ! Local 'i'
j:=4
writeln("Inside of myproc, i=",i," j=",j)
end-procedure
i:=45 ! Global 'i'
j:=10
myproc
writeln("Outside of myproc, i=",i," j=",j)
This code extract displays:
Inside of myproc, i=a string j=4 Outside of myproc, i=45 j=4
Overloading
Mosel supports overloading of procedures and functions. One can define the same function several times with different sets of parameters and the compiler decides which subroutine to use depending on the parameter list. This also applies to predefined procedures and functions.
! Returns a random number between 1 and a given upper limit
function random(limit:integer):integer
returned:=round(.5+random*limit) ! Use the predefined
! 'random' function
end-function
It is important to note that:
- a procedure cannot overload a function and vice versa;
- it is not possible to redefine any identifier; this rule also applies to procedures and functions. A subroutine definition can be used to overload another subroutine only if it differs for at least one parameter. This means, a difference in the type of the return value of a function is not sufficient.
Forward declaration
During the compilation phase of a source file, only symbols that have been previously declared can be used at any given point. If two procedures call themselves recursively (cross recursion), it is therefore necessary to be able to declare one of the two procedures in advance. Moreover, for the sake of clarity it is sometimes useful to group all procedure and function definitions at the end of the source file. A forward declaration is provided for these uses: it consists of stating only the header of a subroutine that will be defined later. The general form of a forward declaration is:
| forward procedure Proc_name [(List_of_params)] or forward function Func_name [(List_of_params)]: Basic_type |
where the procedure or function Func_name will be defined later in the source file. Note that a forward definition for which no actual definition can be found is considered as an error by Mosel.
forward function f2(x:integer):integer function f1(x:integer):integer returned:=x+if(x>0,f2(x-1),0) ! f1 needs to know f2 end-function function f2(x:integer):integer returned:=x+if(x>0,f1(x-1),0) ! f2 needs to know f1 end-function
Suffix notation
Functions which name begins with get and taking a single argument may be called using a suffix notation. This alternative syntax is constructed by appending to the variable name (the intended function parameter) a dot followed by the function name without its prefix get. For instance the call getsol(x) is the same as x.sol. The compiler performing internally the translation from the suffix notation to the usual function call notation, the two syntaxes are equivalent.
Similarly, calls to procedures which name begins with set and taking two arguments may be written as an assignment combined with a suffix notation. In this case the statement can be replaced by the variable name (the intended first procedure parameter) followed by a dot and the procedure name without its prefix set then the assignment sign := and the value corresponding to the second parameter. For instance the statement sethidden(ctl,true) can also be written ctl.hidden:=true. As for the other alternative notation, the compiler performs the rewriting internally and the two syntaxes are equivalent.
The public qualifier
Once a source file has been compiled, the identifiers used to designate the objects of the model become useless for Mosel. In order to access information after a model has been executed (for instance using the print command of the command line interpreter), a table of symbols is saved in the BIM file. If the source is compiled with the strip option (-s), all private symbols are removed from the symbol table — by default all symbols (except parameters) are considered to be private.
The qualifier public can be used in declaration and definition of objects to mark those identifiers (including subroutines) that must be published in the table of symbols even when the strip option is in use.
public declarations e:integer ! e is published f:integer ! f is published end-declarations declarations public a,b,c:integer ! a,b and c are published d:real ! d is private end-declarations forward public procedure myproc(i:integer) ! 'myproc' is published
This qualifier can also be used when declaring record types in order to select the fields of the record that can be accessed from outside of the file making the definitions: this allows to make available only a few fields of a record, hidding what is considered to be internal data.
declarations
public t1=record
i:integer ! t1.i is private
public j:real ! t1.j is public
end-record
public t2=public record
i:integer ! t2.i is public
j:real ! t2.j is public
end-record
end-declarations
Packages
Declarations may be stored in a package: once compiled, the package can be used by any model by means of the uses statement. Except for its beginning and termination (keyword model is replaced by package) a package source is similar to a normal model source. The following points should be noticed:
- all statements and declarations outside procedure or function definitions are used as an initialization routine: they are automatically executed before statements of the model using the package;
- symbols that should be published by the package must be made explicitly public using the public qualifier (see Section The public qualifier);
- parameters of a package are automatically added to the list of parameters of the model using the package;
- as opposed to modules that are dynamically linked, bim files of packages are used only at compilation time — they are not required for execution;
- a package cannot be imported several times by a model and packages publish symbols of packages they use. For instance, assuming package P1 imports package P2, a model using P1 cannot import explicitly P2 (with a uses statement) but has access to the functionality of P2 via P1.
The requirements block
Requirements are symbols a package requires for its processing but does not define. These required symbols are declared in requirement blocks which are a special kind of declaration blocks in which constants are not allowed but procedure/functions can be declared. The symbols of such a block have to be defined when the model using the package is compiled: the definitions may appear either in the model or in another package but cannot come from a module. Several packages used by a given model may have the same requirements (i.e. same identifier and same declaration). It is also worth noting that a package inherits the requirements of the packages it uses.
requirements an_int:integer s0: set of string bigar: array(S0) of real procedure doit(i:integer) end-requirements
File names and input/output drivers
Mosel handles data streams using IO drivers: a driver is an interface between Mosel and a physical data source. Its role is to expose the data source in a standard way such that from the user perspective, all data sources can be accessed using the same methods (i.e. initializations blocks, file handling functions). Drivers are specified in file names: all Mosel functions supporting IO operations though drivers can be given an extended file name. This type of name is composed of the pair driver_name:file_name. When Mosel needs to access a file, it looks for the specified driver in the table of available drivers. This table contains all predefined drivers as well as drivers published by modules currently loaded in memory. If the driver is provided by a module, the module name may also be indicated in the extended file name: module_name.driver_name:file_name. Using this notation, Mosel loads the required module if necessary (otherwise the file operation fails if the module is not already loaded). For instance it is better to use mmodbc.odbc:database than odbc:database.
The file_name part of the extended file name is specific to the driver and its structure and meaning depends on the driver. For instance, the sysfd driver expects a numerical file descriptor so file sysfd:1 is a valid name but sysfd:myfile cannot work. A driver may act as a filter and expects as file_name another extended file name (e.g. zlib.compress:mem:0x123/23).
When no driver name is specified, Mosel uses the default driver which name is an empty string (myfile is equivalent to :myfile). This driver relies on OS functions to access files from the file system.
The null driver can be used to disable a stream: whatever
written to file "null:" is ignored and reading from it is like
reading from an empty file.
The tee driver can only be open for writing and expects as file name
a list of up to 6 extended file names separated with `&': it opens all
the specified files and duplicates what it receives to each of them. If only
one file is given or if the string terminates with `&', output is
also sent to the default output stream (or error stream if the file is
used for errors). For instance, writing to the
file "tee:log1&log2&" has the effect of writing at the same
time to files "log1" and "log2" as well as sending a copy to
the console.
The other predefined drivers (sysfd, mem, cb and raw) are useful when interfacing Mosel with a host application. They are described in detail in the Mosel Libraries Reference Manual.
Handling of input/output
At the start of the execution of a program/model, two text streams are created automatically: the standard input stream and the standard output stream. The standard output stream is used by the procedures writing text (write, writeln, fflush). The standard input stream is used by the procedures reading text (read, readln, fskipline). These streams are inherited from the environment in which Mosel is being run: usually using an output procedure implies printing something to the console and using an input procedure implies expecting something to be typed by the user.
The procedures fopen and fclose make it possible to associate text files to the input and output streams: in this case the IO functions can be used to read from or write to files. Note that when a file is opened, it is automatically made the active input or output stream (according to its opening status) but the file that was previously assigned to the corresponding stream remains open. It is however possible to switch between different open files using the procedure fselect in combination with the function getfid.
model "test IO"
def_out:=getfid(F_OUTPUT) ! Save file ID of default output
fopen("mylog.txt",F_OUTPUT) ! Switch output to 'mylog.txt'
my_out:=getfid(F_OUTPUT) ! Save ID of current output stream
repeat
fselect(def_out) ! Select default ouput...
write("Text? ") ! ...to print a message
text:=''
readln(text) ! Read a string from the default input
fselect(my_out) ! Select the file 'mylog.txt'
writeln(text) ! Write the string into the file
until text=''
fclose(F_OUTPUT) ! Close current output (='mylog.txt')
writeln("Finished!") ! Display message to default output
end-model
A copy of the original file is saved prior to the update (i.e. the original version of fname can be found in fname˜).
If you have any comments or suggestions about these pages, please send mail to docs@dashoptimization.com.