MC 202 - EF - Atividade de Laboratório no. 8
Descrição do Problema: Avaliação prática de Tabelas de Hashing
[ alterado em 17/10]
O objetivo desta atividade é fazer uma avaliação
de desempenho ao se utilizar tabelas de hashing
para manter as palavras que ocorrem num texto de entrada e a sua
freqüência. Esta atividade é bem parecida
à anterior (laboratório 6): o texto de entrada
será o mesmo e os 'indicadores de desempenho' utilizados
serão praticamente os mesmos. Você deverá fazer
vários testes alterando valores de configuração
como
- parâmetros da função de espalhamento
- tamanho da tabela
- tratamento de colisões
Para cada teste, o programa deverá contar o
número de comparações, tanto de palavras como as
comparações caracter a caracter.
O texto de entrada
O arquivo texto de entrada consiste na junção de alguns
contos e poemas de Edgar Allan Poe, baixados da rede(http://virtualbooks.terra.com.br). Esse arquivo pode ser baixado de TextosEdgarAllanPoe.txt.
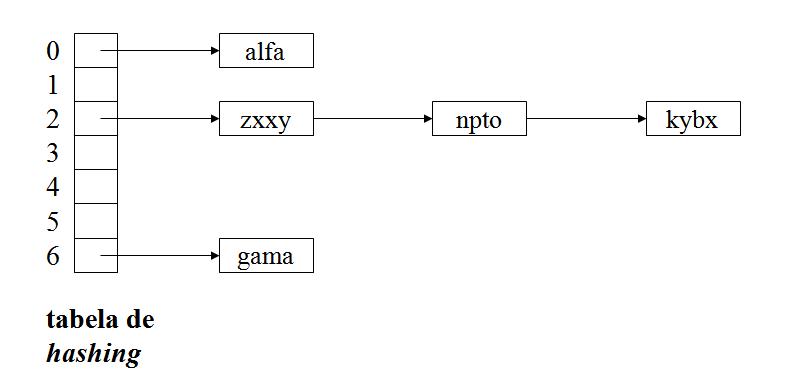
A Tabela de Hashing
A tabela de hashing utilizada deve seguir a descrição feita em sala: o item k
da tabela de hashing contém um apontador para a lista de valores
(palavras) cujo valor da função de hashing é igual
a k (em outras
palavras, as colisões são mantidas numa lista ligada).
A figura abaixo ilustra a idéia geral da tabela de
hashing.
O que deve ser feito
Para realizar a avaliação solicitada, o seu programa
deverá tomar por base os números obtidos na atividade de
laboratório 6. Você deverá realizar vários
testes com as seguintes variações:
- função de hashing: experimentar pelo menos 3 variações da função de hashing, alterando a forma ou os parâmetros utilizados para calcular o valor de hashing.
- tabela de hashing: experimentar pelo menos 5 valores para o
tamanho da tabela de hashing. Como você já sabe que o
texto de entrada contém aproximadamente 12 mil palavras
diferentes, um bom ponto de partida para o tamanho da tabela
é um valor entre 1/2 e 1/4 desse valor.
- tratamento de colisões: a descrição da
tabela feita acima recomenda que as palavras com o mesmo valor de
hashing sejam mantidas numa mesma lista ligada. As
inserções nessa lista podem ser feitas no início e
ao final da mesma. As duas variações devem ser
consideradas no seu teste.
Ao testar as diversas variações descritas acima,
você deve descartar (e substituir) os casos em que o
número de comparações de 'caracter a caracter'
sejam maiores que o menor dos valores obtidos na atividade 6 (ou seja,
você só deve considerar as variações que
apresentem indicadores 'melhores' que aqueles apresentados na
atividade 6).
Para cada um desses 30(!) casos, o programa deve fazer o seguinte:
- Construção da tabela de hashing:
ler o arquivo de entrada e criar uma tabela de hashing para manter as
palavras contidas no mesmo (sem repetições).
- Avaliação da tabela de hashing para a busca das palavras:
ler o arquivo de entrada e procurar cada palavra que ocorre no mesmo na
tabela de hashing criada no passo anterior. As ocorrências de
cada palavra devem ser contadas nesta fase. Ao fazer a busca por uma
palavra na tabela de hashing, o seu programa deve contar as comparações de palavras (strings) e caracteres.
Resultados Apresentados
Para cada um dos 30 casos descritos acima, o seu programa deve apresentar os seguintes dados:
- número total de comparações 'palavra a palavra' e 'caracter a caracter'.
- número mínimo, máximo e médio de colisões.
- 'percentual de ocupação' da tabela de hashing (percentual de listas não vazias na tabela)
O programa deverá identificar o 'melhor caso', ou seja, aquele
que apresentar o menor número de comparações
'caracter a carater', e para ele, listar a configuração
utilizada: parametrização da função de
hashing, tamanho da tabela e política
de inserção na lista de colisões (no início ou ao final).
Além desses resultados, você deverá entregar
também um arquivo texto explicando o porquê dos
resultados obtidos.
Funções auxiliares
Leitura do arquivo e comparação de caracteres
Para a contagem do número de comparações, tanto
'palavra a palavra' como 'caracter a caracter', você pode
utilizar o código a seguir, que é o mesmo recomendado para a atividade 6. Nesse código, a
função strComp() substitui a função strcmp() definida em <string.h>, e pode ser utilizada para a busca por um string.
[alterado em 17/10]
#define GT 1
#define EQ 0
#define LT -1
/***** contadores de comparações ********/
int compCount = 0;
int chCompCount = 0;
/***** (re)inicialização dos contadores de comparações *****/
void resetCounters(){
compCount = 0;
chCompCount = 0;
}
/******* comparação de strings ********/
/**** e contagem das comparações ****/
int strComp(char *a, char*b){
compCount++;
for(;;){
chCompCount++;
if(*a == '\0') if(*b == '\0') return EQ; else return LT;
if(*b == '\0') return GT;
if(*a < *b) return LT;
if(*a++ > *b++) return GT;
}
}
Para a leitura do arquivo e para separar as palavras do mesmo,
você pode utilizar o código a seguir. Esse código
utiliza a função tolower() definida em <string.h>
.
/****************************************************
funções auxiliares para acesso ao arquivo texto
*****************************************************/
char lastCh = '\0'; /* último caracter lido */
FILE* inputFile = NULL; /* arquivo de entrada */
int wordCount = 0; /* contador de palavras */
/*** habilita o arquivo para leitura ***/
void initInputFile(char* fName){
inputFile = fopen(fName,"r");
lastCh = tolower(fgetc(inputFile));
wordCount = 0;
}
/*** encerra a sessão de leitura do arquivo ***/
void closeInputFile() { close(inputFile); }
/* 'pega' o próximo nome do arquivo de entrada. */
/* Devolve NULL se chegar ao final do arquivo */
char* getName() {
char name[30];
int idx = 0;
char * res = NULL;
/* pular caracteres que não interessam */
while((lastCh != EOF) && ((lastCh < 'a') || (lastCh > 'z'))) lastCh = tolower(fgetc(inputFile));
while((lastCh >='a') && (lastCh <='z')){
name[idx++] = lastCh;
lastCh = tolower(fgetc(inputFile));
}
if(idx == 0) return NULL;
res = (char*)malloc(idx+1);
name[idx]='\0';
wordCount++;
strcpy(res,name);
return res;
}
O trecho de código a seguir mostra um exemplo de uso
dessas funções numa 'sessão' para listar as
palavras contidas
num arquivo.
initInputFile("arquivo.txt");
name = getName();
while(name != NULL){
printf("nome:[%s]\n",name);
name = getName();
}
closeInputFile();
Função de Hashing
A função mostrada a seguir pode ser utilizada como base
para as variações a serem testadas no seu programa (essa
pode ser uma das 3 variações solicitadas). Note que nessa
função, os contadores compCount e chCompCount
estão sendo atualizados. Isso está sendo feito porque o
acesso à palavra e aos seus caracteres feitos na
função têm um custo associado e esses custos, por uma
questão de simplificação serão considerados
equivalentes aos das comparações. Suas variantes da devem manter essa consideração. Nessa
função, HSIZE representa o tamanho da tabela de hashing.
#define HFACTOR 2
int hashFunction(char *info){
int i = 0, v = 0, f = 1;
if(info == NULL) {printf("erro em hashFunction\n"); return -1; }
compCount++;
for(i = 0;;i++){
if(info[i] == '\0') break;
chCompCount++;
v = (f*v)%HSIZE+info[i];
f = f*HFACTOR;
}
return v % HSIZE;
}
Outra variação para essa função, baseada na
função de hashing padrão utilizada pelas
bibliotecas de apoio da linguagem Java pode ser a seguinte:
int hashFunction(char *info){
int h = 0, i = 0;
if(info == NULL) { printf("erro em hashFunction\n"); return -1; }
compCount++;
for(i=0;; i++){
if(info[i] == '\0')break;
chCompCount++;
h = (31*h)%HSIZE+info[i];
}
return h % HSIZE;
}
Liberação de Memória
Esta aplicação utiliza muita memória (são
30 testes, alocando uma quantidade significativa de memória).
Sendo assim,
toda memória alocada seja liberada ao final de cada teste. Essa memória inclui:
- a tabela de hashing (se for alocada através de malloc() ou equivalente).
- nós utilizados nas listas de colisões
- strings alocados na leitura do arquivo de entrada (pela
função getName() ou alguma substituta). Notar que esses
strings podem ser inseridos na tabela ou não; em qualquer dos
casos, a memória correspondente deve ser liberada em algum
momento.
Data de Entrega: 20/10/08