Last edited on 1999-01-31 07:23:11 by stolfi
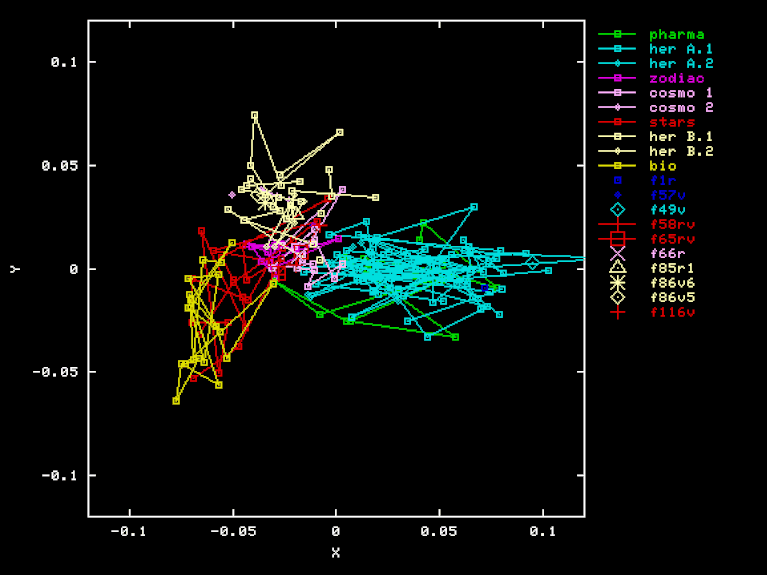
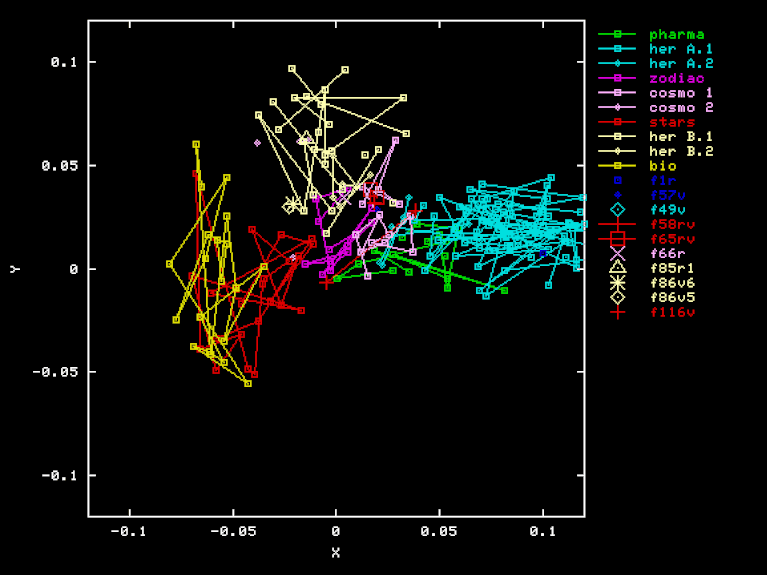
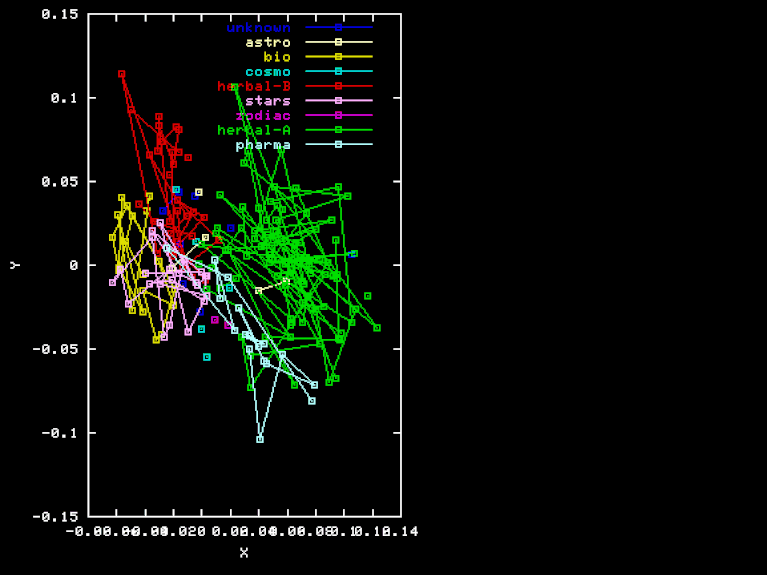
The plots have several notable features:
The pages are obviously lumped into a few well-separated clusters, which correspond to major sections:
We cannot say much about the other sections ("Astronomical", "Cosmological", and "Zodiac"), because only a couple of pages have been transcribed from each. We will ignore them in the rest of this discussion.
There are several possible explamantions for this clustering:
Artifacts of analysis: Could the clusters be merely artifacts of the plot construction process? Note that the number of coordinates for each page (50 or more) is comparable to the number of pages (about 200); it may be that any random sample with these parameters has some 3-dimensional projection that looks as lumpy as these plots; and my axis selection method happens to pick precisely that projection space.
This explanation seems unlikely, however, because it does not explain why the clusters happen to coincide with the traditional sections. The axes selection process used the position of the centroids of some sections, but not of the individual pages. If the page points were random samples from a single distribution, one would not expect the sections to be cleanly separable along that direction.
Graphical artifacts: Perhaps the clustering is an optical illusion, induced (for instance) by the colored lines that connect pages from the same section.
The colored lines surely make the clusters stand out more clearly, but if we look closely at the points themselves, we see that the clusters are indeed compact and well-separated, independently of the lines.
Transcriber bias: Since the input text was a pastiche of many translations, perhaps the clustering is due to different sections being transcribed by different people, who make systematic errors on borderline characters?
This concern is lessened by the use of the majority version. Each position in the VMS has been now transcribed at least twice, including a full transcription by Takeshi Takahashi. So we took for each character the majority of all its transcriptions, or "*" if there is not clear majority. This rule should remove a good deal of the transcriber bias.
Moreover, a comparison of the word and element frequencies in, say, Herbal-A and Herbal-B shows that the differences are too extenive and arbitrary to be the result of transcription errors.
Incomplete data: This was a concern for previous verions of these plots, where the many clusters of untranscribed pages were probably creating artificial gaps in what should have been one continuous cloud.
This hypothesis is strenghtened by comparison with René's René's plots from the Teddington meeting, which hardly show any gaps between the clusters (except when the astro/cosmo pages are deleted!)
However now we have a complete transcription, so if the gaps are due to missing material, it must be missing in the original text.
Handwriting changes: Another possibility is that the different statistics in each section are a side effect of changes in the scribe's handwriting, which affected the way marginal characters got read by the transcribers. (In that case, the clean separation between the various clusters would suggest that each section was written in a short period of time, with longer intervals between sections --- during wich the scribe's handwriting continued to evolve.
This hypothesis is rather unlikely. As said above, The statistical differences between various sections are too large to be due to transcription errors.
Different topics: Perhaps the differences between clusters are due to differences in subject matter, or grammatical style (active/passive, present/past/future, indicative/imperative/subjunctive, personal/impersonal, etc.)
This is a possibility. Once more, however, this theory has trouble explaining the extensive change in vocabulary and OKOKOKO element frequencies---which affect most of the most popular words.
Different encodings: The clusters could be due to the use of different encodings (alphabets and/or spelling rules) for each section --- either by distinct scribes, or by the same scribe at different times.
Different languages: We may be seeing several different languages, dialects, or regional accents (the latter presumes that the text is a dictation, with phonetic spelling, taken by a partially ignorant scribe.)
There is no clear evidence for clustering, or any other structure, within each section. (Again, it may be that we simply have chosen the wrong projection.)
In fact, the pages seem to jump fairly randomly within each cluster. Some of that randomness may be due to sampling error, given the relatively small amount of text in many pages. The randomness seems I should have computed and plotted the sampling error ellipses...
Another conspicuous (non-)feature is the "random" placement of the clusters in space. There seems to be no obvious alignment between the cluster centers, and no obvious ordering of the clusters along a line.
It is not clear how to interpret this observation. At first, I thought it was a point against the "gradual evolution" theory . In gradual evolution (due to aging, practicing, or increasing slopiness), the page points should form an elongated cloud; whereas I saw only discrete clusters.
However, after seeing René's paper, I don't know what to think. René sees a single elongated cloud (even though it has a 90 degree turn at some point), and takes that as an argument for gradual evolution.
Comparing the plots based on words or wordclasses to the ones based on elements, we see that clustering is much more evident in the former than in the latter.
This observation seems consitent with many theories about the nature of clustering. It would be expected if the section clustering is due to different but related languages or dialects. But it couls also be explained by different subject matter or grammatical style (e.g. different usage of "-ed" and "will" in narrative vs. romance). It could also be due to a change in spelling rules. And so on...
{kind=link}
{kind=link}
{kind=link}
{kind=link}