Last edited on 2002-01-19 11:54:31 by stolfi
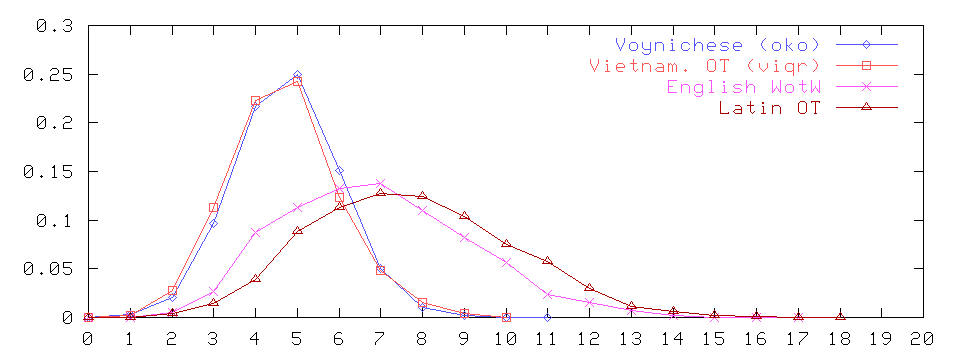
Plot (1) above compares the distribution of word lengths in four different language samples: (a) the VMS text ("Voynichese") without labels, (b) the Pentateuch in Vietnamese (Cadman), (c) Well's "War of the Worlds" in English, and (d) the Pentateuch in Latin (Vulgate).
Here are some technical details. Each histogram in (1), and in all plots that follow, was derived from the sample's lexicon, not from its token stream --- which is to say, each distinct word was counted only once, ignoring its capitalization and how many times it occurred in the sample. The Voynichese text was taken from the majority vote version, discarding all unreadable or contentious words. All texts were truncated to be 35027 tokens (not words) long, the same size as the VMS sample; they contained, respectively, 6525, 1706, 4869, and 6634 distinct words. For Latin and English, the word length was defined in the obvious way, as the number of letters in the language's native spelling. For Vietnamese, we counted the number of bytes in the VIQR encoding, which is essentially the national standard spelling (Quo^'c Ngu+~) with each diacritic represented as separate byte. For Voynichese, the length was defined as the number of elements in the OKO "alphabet": basically, the EVA groups ch, sh, ee and the platform gallows are counted as single letters, and the symbols a o y e i are assumed to be part of the preceding letter.
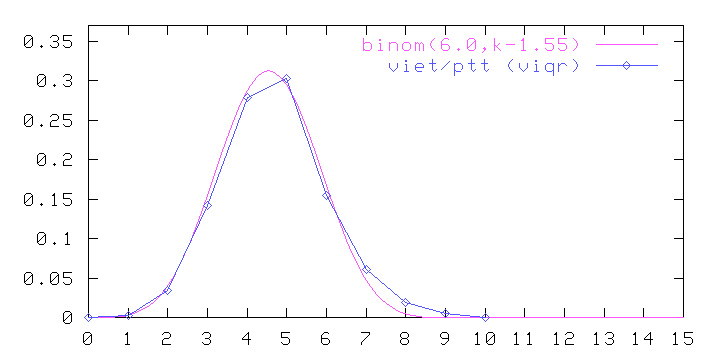
If you recall, about a year ago I was quite upset when I found that the VMS word length distribution (in a simpler alphabet) matched almost exactly the 9-coin binomial distribution shifted by 1, choose(9,k-1), as shown in plot (2) below:

Indeed, I was so impressed by (2) that I suddenly lost faith in my long-cherished Chinese theory. I just could not believe that such mathematical symmetry could be found in a natural language. In my mind, the only process that could generate that plot was a codebook-based system with word codes written in some Roman-like notation, as explained in the previous page Indeed, it is not hard to invent a Roman-like number system that will produce the right word-length statistics.
Well, it seems I was wrong again... Last week I finally got some usable samples of Chinese, Vietnamese, and Tibetan, and started doing the experiments which I should have done a year ago. These being monosyllabic languages, I was expecting their word-length distributions to resemble that of Voynichese, in having a sharp cut-off at a certain maximum length. However, apart for this qualitative resemblance, I was expecting their histograms to be as irregular and asymmetric as those of polysyllabic languages, shown below (3)-(4).
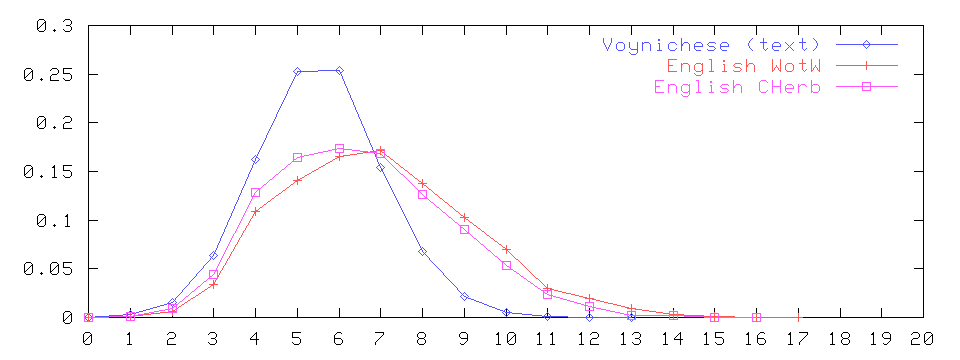
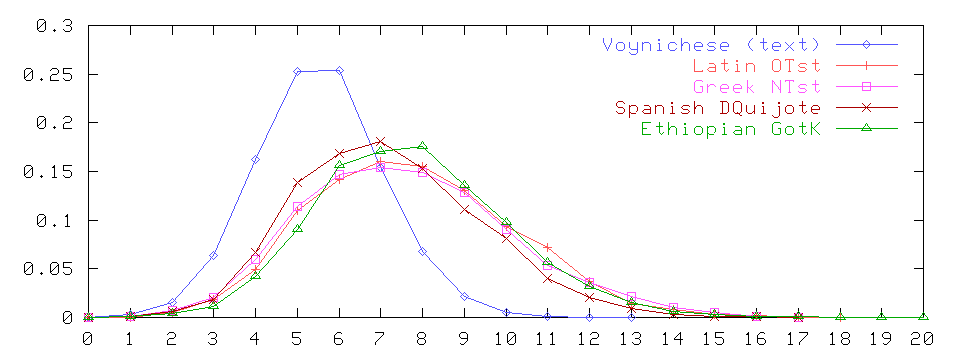
Indeed, when I finally plotted the word length distributions for those East Asian languages (5), they were basically what I had expected: compact and tail-less, even more so than that of Voynichese:

The VMS alphabet that I was using in all these tests (labeled "bgly" in the plots) was not OKO, but a simpler one where ch, sh, and the platform gallows are counted as single letters, but a o y e i are counted as separate letters. As figure (5) shows, with this alphabet the VMS word length histogram is wider than that of Vietnamese, and shifted to its right. The OKO-based plot (1) above was done almost as an afterthought, just because I had the tools at hand. As you can imagine, I was quite surprised by the close coincidence between the two plots.
Obviously, my intuition was (again) flatly wrong: the East Asian monosyllabic languages *do* have symmetric, binomial-like word length distributions, just like Roman numerals. So, the symmetry of plot (1) is not only compatible with the Chinese theory, but in fact considerably strengthens the word-length length distribution argument: the resemblance is quantitative, not just qualitative.
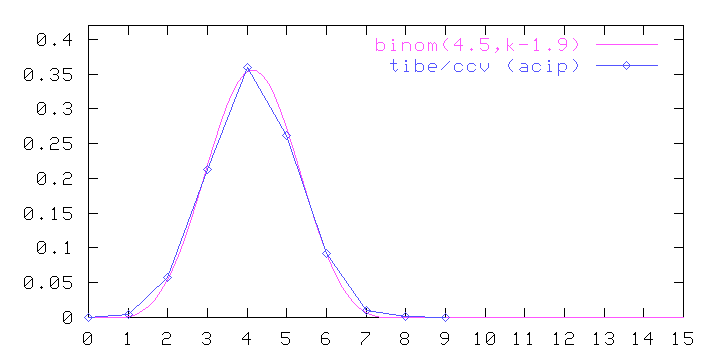
Is the match between the two curves anything more than a meaningless coincidence? Well, as figure (6) shows, the Vietnamese word length distribution in VIQR is quite close to binomial, too, only with different parameters --- more like choose(6,k-1.55). Indeed, figures (7) and (8) show that to be the case for Tibetan and Chinese in standard romanizations, too: the plots only look asymmetric because the underlying (symmetric) binomial is not centered on an integer value:
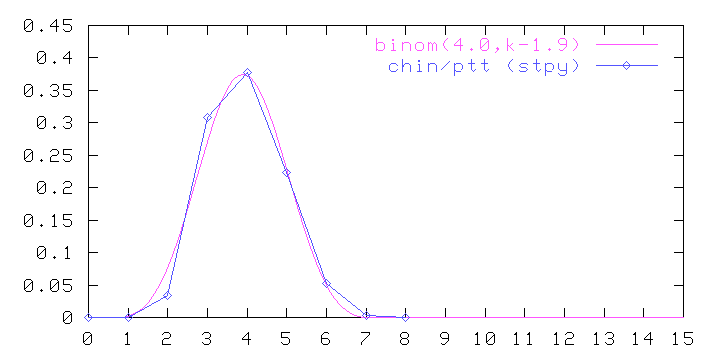
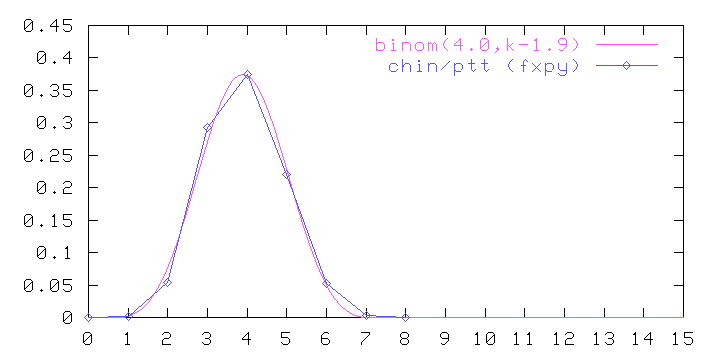
In fact, the deviations from binomial seen on the left edge of the Chinese plot can be ascribed to "wrong" decisions made by the linguists who designed the pin-yin romanization system. Specifically, in Chinese syllables that begin with an "i" sound, they arbitrarily inserted an initial dummy "y", presumably to retain some compatibility with previous romanization systems. A dummy initial "w" was similarly inserted before syllables beginning with "u". These rules have the effect of lengthening the pin-yin spelling of some consonant-less (hence shorter) words, which could explain the discrepancies noted above. Indeed, we can improve the match by re-encoding the Chinese sample through the mapping "yi->i", "wu->u", as shown by (9):
It is worth noting that the binomial curve assumed in this model has exactly three adjustable parameters: width, height, and horizontal shift (or mean value). Therefore, a match to a five- or seven-point histogram is a significant result, even considering that we allow the parameters to be fractional.
Why should those languages have a binomial-like syllable-length distribution? Well, as observed in the previous page, if you add many random variables with arbitrary distributions, you get a random variable with a binomial-like, bell-shaped distribution, which approaches a Gaussian as you add more and more terms. (Technically, the histogram of the sum of two independent variables is the convolution of their histograms; and the convolution of N arbitrary histograms, as N increases, generally becomes more and more like a Gaussian distribution.)
Now, unlike a polysyllabic word, a single syllable has only a fixed number N of phonetic "slots" (attributes), corresponding to separate muscular controls; and each slot can have a finite number of possible values. In the Chinese syllable, for instance, the initial consonant is one slot, which can have some 20 values including "silent". Another slot would be the glide before the main vowel ("i", "u", or "none", as in "lian", "luan", or "lan"). The main vowel, the secondary glide, the final consonant, and the syllable tone would be the other slots.
In principle, then, a syllable could be written as a sequence of N symbols, each corresponding to one phonetic slot. However, that would be a rather inefficient encoding, because the values of each slot have highly different frequencies in common use. (In particular, the most frequently used words will tend to use slot values that can be articulated with less time or effort.)
For that reason, almost all scripts follow the model of Roman numerals, where one value for each slot is assigned as "default" and not written, while the other values are mapped to distinctive symbols. Thus the "silent" consonant and "none" glides are omitted in pin-yin; the "a" vowel is omitted in Hindu scripts; and the mid level tone of Vietnamese is not marked in Quo^'c Ngu+~. Moreover, if a slot has many possible values, some of them are often encoded by sequences of two or more symbols, such as "ch" in Chinese or "u+" in Vietnamese.
Thus, in all those scripts, the written syllable is the concatenation of N variable-length strings. Assuming that the value of a slot is to some extend independent of other slots, the word-length histogram is therefore the convolution of N slot-length histograms, and therefore is expected to resemble a binomial distribution.
Yes, what next?