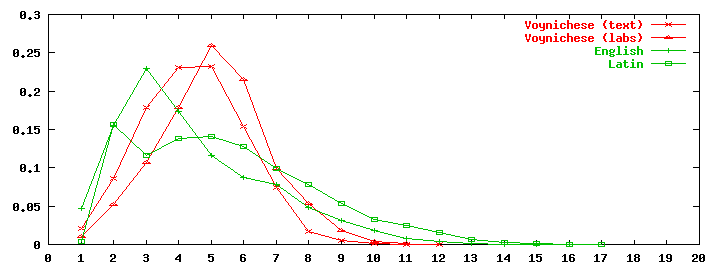
Figure 1 - Token length distributions.
Last edited on 2002-02-28 00:03:49 by stolfi
A word is an abstract sequence of symbols; a token is an occurrence of a word in the VMS text (delimited by blanks, line breaks, etc.) The length of a word or token is the number of symbols it contains. For this page, we will define symbol as Currier did; i.e. EVA ch ans sh will be counted as single symbols, and so are EVA cth, ckh, etc..
If we plot the relative number of VMS tokens of each length, we obtain the following distributions:
On the other hand, if we plot the relative number of distinct VMS words of each length, ignoring their freqnecies in the text, we get:
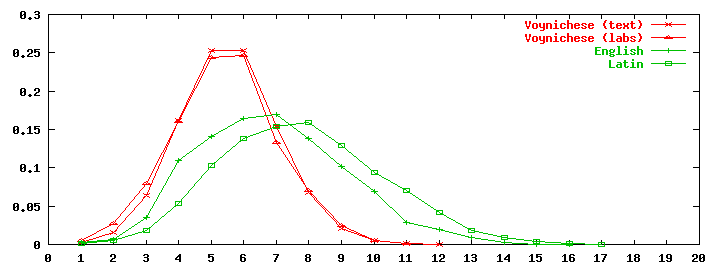
Two things are remarkable about this plot: (1) the surprising coincidence between the text and label distributions (even though the sample sizes differ by an order of magnitude, and the token distributions are quite different); and (2) the almost perfect symmetry of the distribution around its mean (5.5 symbols). These coincidences cry for an explanation.
In fact, the word length distribution matches almost perfectly a binomial distribution for 9 equally-likely coin tosses, shifted by 1 --- which is choose(9,k-1)/29:
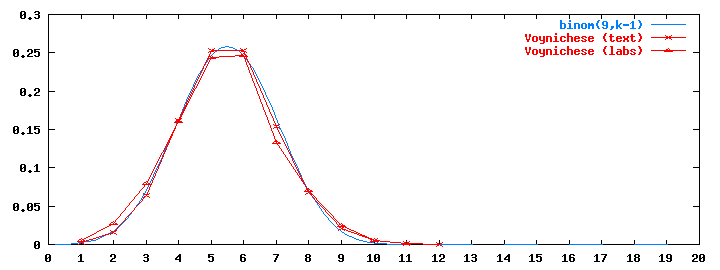
This coincidence suggests that the length of a word chosen at random from the lexicon is 1 plus the sum of nine random binary variables. What does that tell us about the code?
Here is a code that would produce such distribution. Assign to each word of the lexicon a distinct binary number, and then write down the positions of the `1' bits in that number, counting from the units place. Assuming the lexicon contains at most 210 words, the `1' positions are a set of decimal digits. Write those digits in some fixed order (say, descending), and append a marker (say, `#') to each string. For example:
| Binary number | 0 | 1 | 10 | 11 | 100 | 101 | 110 | 111 | 1000 | 1001 | ... |
| Decimal code | # | 0# | 1# | 10# | 2# | 20# | 21# | 210# | 3# | 30# | ... |
Call the resulting strings the decimal codes of the words. Now suppose the lexicon has about $2^9 = 512$ words. If we tabulate the lengths of their decimal codes, we will obtain a binomial distribution, with mean 5.5 and maximum 10 --- the blue curve in figure 3.
The same distribution will result if the digits of the code are scrambled according to some deterministic rule. For instance, we could list the even digits in increasing order, then the `#' marker, then the odd digits in decreasing order:
| Binary number | 10100 | 10101 | 10110 | 10111 | 11000 | 11001 | 11010 | 11011 | 11100 | 11101 | ... |
| Decimal code | 24# | 024# | 24#1 | 024#1 | 4#3 | 04#3 | 4#31 | 04#31 | 24#3 | 024#3 | ... |
Coincidentally, the structure of Voynichese words is quite similar to that of the decimal codes produced by this method. Namely, the symbols within each VMS word are, in some sense, unimodally sorted --- first ascending, then descending. (Rene Zandbergen once suggested that the letters may have been sorted alphabetically within each VMS word. He may have been on the right track...)
Note that if the decimal codes were assigned to the words at random, or in alphabetical order, the token length distribution would be fairly symmetrical, and similar to the word length distribution. On the other hand, if a new code is assigned in sequence to each new word that appears in some plaintext, then the most common words will tend to have shorter codes, and the token length distribution will be biased towards the left --- as in figure 1 above.
Is the above example relevant to the VMS? Well, besides reproducing the word-length distribution, it also reproduces another puzzling feature of Voynichese:
As you may recall, if we let X(w) stand for the boolean variable `word w has a gallows letter', and Y(w) mean `word w has one or more bench letters', then we find that the variables X and Y have uniform distributions over the text (50% `yes', 50% `no'), and are independent of each other --- even though gallows and benches occur next to each other in Voynichese words. The decimal code described above, coincidentally, shows a similar phenomenon: about half of the word codes will have a `9' digit, about half of them will have an `8' digit, and these two `traits' are independent.
In my understanding, all these hints point towards Voynichese words being `numbers' rather than linguistic entities. Therefore, the encoding is probably a codebook-based cipher. (A nomenclator, is that the term?)
Of course, the Voynichese number system must be more complex than the example above. For one thing there doesn't seem to be an obvious marker analogous to `#'. Also, some symbols may occur twice in the same word, and the the eight gallows letters are mutually exclusive. There are also historical/psychological problems with the nomenclator theory: such a system would have been extremely slow to write and read --- why would the author use it to encode a whole book? But who knows...
The source text was the per-character majority-vote transcription, excluding words with unreadable or rare characters (weirdos, EVA *, b, u, v, x, I, etc.) and characters which didn't get a clear majority reading.
Here are the derived files I used for the above analysis: