Escrevendo um algoritmo
Nós já sabemos o que é um algoritmo. Ele é um texto com diversas instruções. Normalmente, podemos imaginar que um algoritmo será executado por um certo robozinho. Esse robô é o processador que irá executar as instruções do algoritmo, então é fundamental que só demos a ele ordens bem básicas, que ele seja capaz de cumprir.
Assim, queremos escrever um algoritmo que só contenha instruções elementares. Mais do que isso, é importante projetar um mecanismo que diga ao robô qual é a próxima instrução a ser executada ou quando o algoritmo termina. Por isso, nosso algoritmo terá algumas instruções de controle que digam a ordem e a forma em que as ações são executadas.
Estruturas de controle
Vamos listar as estruturas de controle mais comumente utilizadas ao escrever um algoritmo:
-
O sequenciamento direto é a convenção do nosso algoritmo que determina que uma instrução escrita antes no texto deve ser executada antes. Normalmente, é determinada implicitamente. Por exemplo, se escrevermos uma instrução por linha, então sabemos que cada linha é executada em ordem; se separarmos as instruções por ponto-e-vírgula, então podemos imaginar que esse ponto-e-vírgula significa “e depois faça”.
-
O desvio condicional é uma estrutura de controle que permite que a execução de um algoritmo tome caminhos diferentes, dependendo dos dados de entrada e dos dados computados anteriormente. Normalmente tem a forma “se Q, então faça A, do contrário faça B”, ou apenas “se Q, então faça A”. Nessas frases, Q é uma condição, ou uma pergunta, cuja a resposta é sim ou não e pode ser testada por nosso robô.

Você pode se perguntar como a execução de um algoritmo pode levar tempo diferente se o tamanho do texto que o descreve é fixo. Se tivéssemos apenas os tipos de controle acima, então toda execução levaria praticamente o mesmo tempo. Para executarmos uma instrução ou um conjunto de instruções um número variável de vezes, precisamos das chamadas estruturas iterativas. Cada parte da execução em que executamos esse conjunto de instruções uma vez é chamada de iteração.
-
A iteração limitada é a estrutura mais comum de iteração e é normalmente da forma “repita A exatamente N vezes” ou muitas outras vezes pode ser da forma “para cada item I da lista L, faça A”. Essa estrutura de controle pode ser utilizada, por exemplo, no exemplo da soma dos preços da lista de compra, que vimos anteriormente.
-
A iteração condicional é outra estrutura de controle iterativa que é utilizada quando não sabemos no início quantas vezes precisamos iterar. Normalmente, tem as formas “repita A até que Q valha” ou “enquanto Q, faça A”. De novo, Q é uma condição que pode ser testada por nosso robô.
As estruturas iterativas normalmente são chamadas de laços ou loops.
Vamos reescrever o algoritmo para o exemplo da lista de compras, mas dessa vez vamos deixar explícitas as estruturas de controle utilizadas. Primeiro, vamos supor que não conhecemos o número de elementos da lista no início da execução. Nesse caso, podemos repetir um conjunto de instruções condicionalmente, dependendo se já consideramos o item no final da lista.
(1) tome nota do número zero;
(2) aponte para o primeiro item da lista;
(3) some o valor do item apontado ao número anotado;
(4) enquanto o item apontado não está no final da lista, faça:
(4.1) aponte para o próximo item da lista;
(4.2) some o valor do item apontado ao número anotado;
(5) devolva o número anotado.
Agora supomos que nosso algoritmo recebe não somente a lista de
compras como o número de itens que ela contém, que representaremos
pela letra N.
(1) tome nota do número zero;
(2) aponte para o primeiro item da lista;
(3) some o valor do item apontado ao número anotado;
(4) repita o seguinte N - 1 vezes:
(4.1) aponte para o próximo item da lista;
(4.2) some o valor do item apontado ao número anotado;
(5) devolva o número anotado.
Finalmente, pode ser que o hardware utilizado já sabe como realizar uma ação determinada sobre cada elemento de uma lista. Nesse caso, seria mais simples escrever algo como:
(1) tome nota do número zero;
(2) para cada item da lista:
(2.1) some o valor do item atual ao número anotado;
(3) devolva o número anotado.
Combinando estruturas
O que torna os algoritmos particularmente ricos é a possibilidade de combinar as diversas estruturas de controle. Por exemplo, podemos executar um laço dentro do conjunto de ações de uma estrutura condicional. Mais do que isso, podemos executar um laço dentro do conjunto de ações de outro laço. Nesse último exemplo, chamamos o primeiro de laço interno e o segundo de laço externo. E assim por diante!
Já deve dar para perceber que os algoritmos podem ficar cada vez mais diversos e mas ricos — e, algumas vezes, mais complexos! Cada algoritmo pode ser mais ou menos complicado. Isso vai depender do problema que queremos resolver.
Vamos tentar fazer um algoritmo que ordena um conjunto de cartas.

Uma maneira de fazer isso é primeiro colocar as cartas uma do lado da outra. Depois, basta percorrer as cartas várias vezes, da esquerda para a direita trocando cartas adjacentes que estejam fora de ordem. Quando não encontrarmos nenhum par de cartas fora de ordem, sabemos que as cartas estão ordenadas. Esse é um algoritmo chamado de bubble-sort, ou ordenação da bolha. A ideia é que as cartas maiores vão sendo empurradas para o final, como se fossem bolhas.

Na verdade, o bubble-sort é um algoritmo bem lento e você ainda vai aprender diversos algoritmos que são muitas vezes mais rápidos. Mas, por enquanto, vamos nos concentrar em escrever esse algoritmo. Primeiro, precisamos saber quantas vezes precisamos percorrer a sequência de cartas. Depois da primeira vez que percorremos as cartas, deve ser fácil se convencer de que a maior carta estará no final. Depois da segunda vez, a segunda maior carta já estará na posição correta e assim por diante. Assim, se o número de cartas é N, então basta percorrer o baralho N - 1 vezes.
(1) repita o seguinte N − 1 vezes:
(1.1) aponte para a primeira carta;
(1.2) repita o seguinte N - 1 vezes:
(1.2.1) compare a carta apontada atualmente com a seguinte;
(1.2.2) se as cartas estiverem fora de ordem, inverta-as;
(1.2.3) aponte para a próxima carta.
Esse é um exemplo de algoritmo em que utilizamos e combinamos diversas estruturas de controle. Tente identificá-las!
Desenhando um algoritmo
Ao invés de escrever um algoritmo, também podemos representá-los utilizando desenhos. Há diversas maneiras de desenhá-los, mas talvez a maneira mais comum é criar o que chamamos de “diagrama de fluxo”, ou em inglês, “flowchart”.
Em um diagrama de fluxo, cada instrução elementar é representada por um retângulo e cada desvio condicional é representado por um losango. O objetivo é entender qual o fluxo de execução do algoritmo. Assim, saindo de cada retângulo há um arco que aponta para a próxima instrução a ser executada. Como a instrução executada depois de um desvio condicional depende da resposta, sim ou não, a partir de um losango há dois arcos, um para cada possibilidade.
Vamos fazer um desenho de nosso algoritmo para somar os itens de uma lista de compras.

Perceba que as estruturas iterativas correspondem ao desenho de um circuito fechado no diagrama de fluxo. Isso explica a nomenclatura de laço.
Sub-rotinas
Algumas vezes, os algoritmos podem ficar mais e mais complicados. Assim nossos algoritmo ou diagramas de fluxo podem ficar cada vez maiores. Vamos ver um exemplo de como isso pode acontecer.
Suponha que, na nossa lista de compras, há, não somente o valor de cada item, mas também o tipo. Cada item pode ser de alimentação, limpeza, vestuário, eletrônico etc. Dependendo do supermercado a que vamos, não vamos conseguir comprar todos os itens. Se no supermercado mais próximo pudermos comprar apenas itens de alimentação e limpeza, então precisamos saber o quanto vamos gastar com esses tipos de item. Vamos modificar o algoritmo anterior.
(1) tome nota do número zero;
(2) aponte para o primeiro item da lista;
(3) se o item apontado é do tipo "alimentação":
(3.1) some o valor do item apontado ao número anotado;
(4) repita o seguinte N - 1 vezes:
(4.1) aponte para o próximo item da lista;
(4.2) se o item apontado é do tipo "alimentação":
(4.2.1) some o valor do item apontado ao número anotado;
(5) aponte para o primeiro item da lista;
(6) se o item apontado é do tipo "limpeza":
(6.1) some o valor do item apontado ao número anotado;
(7) repita o seguinte N - 1 vezes:
(7.1) aponte para o próximo item da lista;
(7.2) se o item apontado é do tipo "limpeza":
(7.2.1) some o valor do item apontado ao número anotado;
(8) devolva o número anotado.
É claro que há algoritmos mais simples para essa tarefa, mas podemos fazer diversas observações do algoritmo que escrevemos acima. Primeiro, o texto do algoritmo ficou muito maior. Mais importante do que isso, é muito mais difícil entender o que está fazendo esse algoritmo. Tente desenhar o diagrama de fluxo correspondente.
Além disso, observamos que há dois trechos do algoritmo que são muito parecidos e tudo que muda é o tipo de alimento. Podemos então tentar escrever esse trecho de código apenas uma vez. No lugar do tipo de alimento, utilizamos um parâmetro X que pode ser substituído pelo tipo de alimento desejado. Esse trecho de algoritmo é chamado de sub-rotina ou procedimento.
SOMAR ITENS DA CATEGORIA (X)
(1) aponte para o primeiro item da lista;
(2) se o item apontado é do tipo X:
(3.1) some o valor do item apontado ao número anotado;
(3) repita o seguinte N - 1 vezes:
(3.1) aponte para o próximo item da lista;
(3.2) se o item apontado é do tipo X:
(3.2.1) some o valor do item apontado ao número anotado;
No texto acima, X é um parâmetro que será substituído pelo tipo de alimento quando invocarmos essa sub-rotina. Com esse texto, agora podemos invocar ou chamar a nossa sub-rotina duas vezes no algoritmo principal.
(1) tome nota do número zero;
(2) SOMAR ITENS DA CATEGORIA ("alimentação");
(3) SOMAR ITENS DA CATEGORIA ("limpeza");
(4) devolva o número anotado.
Compare esse novo algoritmo com o algoritmo anterior. Ele não ficou
muito mais simples? É importante observar que agora utilizamos uma
instrução que antes não era permitida, que é
SOMAR ITENS DA CATEGORIA. Esta não é uma instrução elementar do
nosso computador original, mas utilizamos como se fosse. O que estamos
fazendo é análogo a ensinar o nosso robozinho a realizar uma nova
atividade, de forma que não precisamos explicar de novo como fazê-la.
Dizemos que estamos criando uma nova abstração, escondendo os
detalhes de implementação.
Podemos desenhar agora um diagrama de fluxo substituindo o trecho do algoritmo da sub-rotina por um retângulo, como uma instrução elementar. Faça isso.
Tipos e estrutura de dados
Por enquanto falamos apenas de ingredientes de uma receita, de números anotados, de listas de itens de compra, de apontamentos para itens etc. Alguns desses elementos aparecem na entrada e na saída, enquanto outros aparecem como objetos intermediários computados durante a execução do algoritmo. A todos esses objetos, chamaremos de dados.
Tipos
Os vários dados aparecem nos mais diversos sabores ou, mais precisamente, nos mais diversos tipos. Os tipos mais comuns utilizados nos computadores são os números, que podem ter diversos subtipos como números inteiros ou números reais, e strings, que representam palavras ou textos nos mais diversos alfabetos.
Nos computadores que consideraremos, os dados são sempre representados de alguma maneira em particular na memória do computador. Assim, precisamos adotar convenções para representar os objetos tratados pelos algoritmos como uma sequência bem definida de bits ou bytes. Por exemplo, enquanto tratamos números inteiros no formato decimal, a representação desses números na memória é binária. Se quisermos representar objetos mais complicados, como uma imagem, vamos precisar definir representações apropriadas — algumas vezes um tanto quanto complicadas, outras vezes mais simples.
É importante que entendamos exatamente qual é o tipo de cada dado que tratamos no algoritmo, pois cada tipo permite operações distintas. Por exemplo, podemos dividir dois números, mas não podemos dividir duas strings.
Variáveis
No algoritmo da soma, referimo-nos a um dado simplesmente como “valor anotado”, que é inicializado com 0 e depois acumula o valor dos itens de compra. O que estamos fazendo é utilizar uma variável. Uma variável não é o valor de um dado em si; ao invés disso, podemos entender uma variável como uma pequena caixa ou célula onde um determinado valor pode ser armazenado. Cada variável tem um tipo correspondente. Podemos imaginar que nessa caixa só cabem valores do tipo correspondente. Assim, podemos armazenar quadrados em caixas do tipo quadrado, mas não um disco.

Normalmente, damos um nome a essa caixa. Por exemplo, ao invés de sempre ter de escrever “número anotado” no algoritmo anterior, poderíamos chamar essa variável de “subtotal”.

Em Computação, chamamos de variável uma célula que pode conter diversos valores distintos em diferentes momentos, ao contrário da Matemática, em que uma variável é apenas um símbolo que representa um valor desconhecido.
Como o valor de uma variável pode mudar, necessitamos de instruções específicas para alterar o valor de uma variável. Essa instrução é chamada de atribuição. Normalmente escrevemos algo como “atribua valor V à variável X”, ou utilizamos uma notação mais simples, como X $\gets$ V, que devemos ler como “a variável X recebe o valor de V”.
Também podemos atribuir um valor de uma expressão, como em X $\gets$ V+1, em que queremos atribuir à variável X o valor de V mais uma unidade. Devemos tomar um cuidado especial, já que muitas vezes o novo valor depende do valor anterior da variável. Assim, podemos ter a instrução X $\gets$ X+1 que significa que o valor da variável X deve ser mudado e que o novo valor é o valor anterior mais um.
Coleções de dados
Retomemos o exemplo da nossa lista de compras. Para representar a entrada, falamos de uma “lista de compras”, mas uma lista de compras pode conter um número indeterminado de itens e cada um deles corresponde a uma variável. Se o número de itens não é fixo, como podemos armazenar os dados de uma lista de compras? Uma tentativa é criar um conjunto fixo de variáveis, uma para cada item. Por exemplo, o primeiro item na variável X, o segundo na variável Y e o terceiro na variável Z. Mas logo você deve perceber que essa estratégia não é boa se tivermos um lista de compras com mais ou menos do que três itens. Para listas maiores, precisaríamos definir mais variáveis e, para listas menores, teríamos variáveis que não fazem sentido!
Como nosso objetivo é escrever um texto de tamanho fixo, mas que possa ser executado com listas de qualquer tamanho, precisamos de uma maneira de nos referir a esses elementos de maneira uniforme. Para isso, vamos utilizar o que chamamos de vetor. Dependendo do contexto, eles também serão chamadoas de listas ou arranjos unidimensionais.
Para tomar um exemplo, vamos tentar representar a nossa sequência de cartas usando um vetor. Por simplicidade, suponha que todas as cartas têm valores diferentes, então vamos ignorar os naipes e dizer que o ás é representado pelo número 1. Assim, a sequência de cartas desenhada acima poderia ser representada pelo seguinte vetor.

Na figura acima, a variável cartas representa toda a sequência de cartas, mas ainda precisamos de algum mecanismo para nos referir a cada um dos elementos. Poderíamos dizer simplesmente “o primeiro elemento de cartas”, mas há um jeito melhor. Vamos adotar uma notação de colchetes: a primeira carta será cartas[1], a segunda será cartas[2] e assim por diante. Começamos a contar a partir de cartas[1] por mera convenção, poderíamos começar também por um outro índice inteiro.
Com essa notação, podemos reescrever nosso algoritmo bubble-sort.
(1) repita o seguinte N - 1 vezes:
(1.1) X ← 1;
(1.2) enquanto X < N:
(1.2.1) se cartas[X + 1] < cartas[X],
então inverta esses elementos;
(1.2.3) X ← X + 1.
Repare que os índices do vetor dependem de uma variável. É isso que permite que um algoritmo de tamanho fixo se refira a listas de tamanho arbitrário.
Linguagens de programação
Pensar apenas em termos de algoritmos é útil para as diversas atividades cotidianas, seja cozinhar, procurar um número telefônico, agendar um compromisso, fazer compras. Mas queremos escrever algoritmos principalmente para utilizar um computador. Por isso, precisamos também entender como fazer com que o algoritmo saia do papel e passe a ser executado pelo computador.
Lembre-se de que dissemos que os computadores são máquinas que só são capazes de realizar tarefas bem simples, como inverter ou zerar bits na memória. Esse conjunto de instruções que o computador é capaz de realizar é o que chamamos de linguagem de máquina. Um algoritmo escrito em linguagem de máquina, por sua vez, é uma sequência de bits e bytes. Para que possamos visualizar um algoritmo em linguagem de máquina, normalmente escrevemos uma representação em texto, em uma linguagem de montagem, ou assembly language. Por exemplo, um trecho de código em assembly se parece com
LOOP: MOV A, 3
INC A
JMP LOOP
Pode parecer surpreendente que essas máquinas realizem tarefas tão elaboradas, como simulações químicas, controle de tráfego aéreo, etc. O que permite que consigamos instruir os computadores a executar tarefas tão elaboradas, mesmo que eles só realizem tarefas bem simples é que nós escrevemos os algoritmos para os computadores em um idioma mais abstrato do que as linguagens de máquina.
Mas quando escrevemos um algoritmo, digamos, em português, estamos escrevendo para uma outra pessoa. Não há computador que genuinamente entenda o que significa “percorrer uma lista”, “adicionar ao número anotado”, etc. Que entenda, por exemplo, “percorra a lista somando os valores”. A principal dificuldade aqui é que o português é uma linguagem ambígua — e o computador não pode adivinhar qual o significado de cada uma dessas instruções.
Para escrever um algoritmo de forma com que o computador entenda, usamos uma linguagem de programação. Por isso, depois de escrito o algoritmo (normalmente em português ou em algum formato parecido), uma pessoa, a programadora traduz esse algoritmo para uma linguagem de programação. Assim, ela transforma um algoritmo em um programa correspondente. Observe que a programadora pode, inclusive, não ser a mesma pessoa que criou o algoritmo.
Uma linguagem que é inambígua para o computador é a própria linguagem de máquina, ou a linguagem de montagem correspondente. Mas isso não deixaria feliz a programadora, que teria que escrever programas imensos, mesmo para tarefas bem simples. Por isso, utilizamos uma linguagem de programação de alto nível, para que escrevamos programas mais parecidos com o algoritmo que nós normalmente escreveríamos, mas que seja inambíguo como exige um computador.
Sintaxe
Uma linguagem de programação normalmente tem uma sintaxe rígida, que é o conjunto de regras que determina quais combinações de símbolos e palavras-chaves podem ser utilizadas. Por exemplo, se em uma linguagem a palavra-chave para ler um número e guardá-lo na variável X for input X, escrever read X iria resultar em um erro de sintaxe. Por mais que uma pessoa entenderia qual o objetivo da programadora ao escrever a instrução errada, um computador não entenderia. A razão para escolher uma palavra input em inglês é para facilitar a leitura do programa, mas uma palavra-chave poderia ser qualquer sequência de símbolos.
Considere o programa a seguir um uma linguagem hipotética.
input N ;
X := 0 ;
for Y from 1 to N do
X := X + Y
end ;
output X
Nessa linguagem, o símbolo := representa uma atribuição, assim
escrevemos X := 0, quando normalmente escreveríamos X $\gets$ 0 nos
nossos algoritmos anteriores. A linguagem pode ter várias estruturas
de controle. Por exemplo, o trecho que começa com for corresponde a
um laço que realiza um conjunto de instruções um determinado número de
vezes variando o valor da variável inteira Y de 1 até N.
Além disso, a ordem com que os símbolos e palavras-chaves aparecem é de fundamental importância. Essa ordem é determinada pela sintaxe. Nessa linguagem hipotética retirada da bibliografia, a sintaxe é definida pelo seguinte diagrama
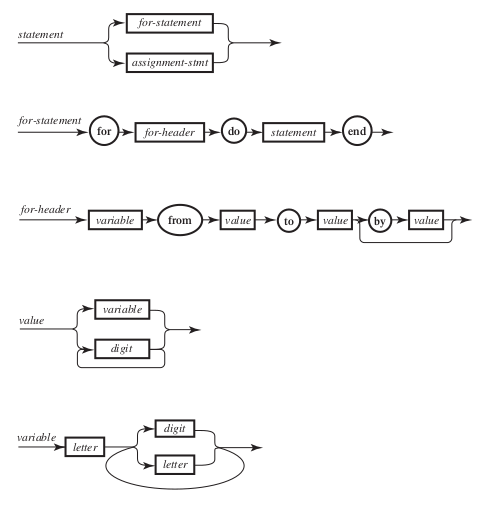
Repare que, após a palavra-chave for, deve vir uma uma sequência
palavras correspondendo a um for-header, cabeçalho do for,
seguindo da palavra-chave do e assim por diante. O cabeçalho, por
sua vez começa com o nome de uma variável, seguido da palavra-chave
from, etc. A sintaxe deve ser seguida rigorosamente, portanto, se
tivéssemos escrito
input N ;
X := 0 ;
for Y to N from 1 do
X := X + Y
end ;
output X
o computador se recusaria a continuar, acusando um erro de sintaxe, mesmo que só tenhamos invertido a ordem de duas palavras-chaves! Existem várias outras maneiras de representar a sintaxe de uma linguagem de programação, mas não precisamos delas agora.
A maioria das linguagens utilizam apenas símbolos e palavras-chaves
para determinar sua sintaxe. Assim, o conjunto de instruções que
correspondem a uma iteração do for acima é terminado com a
palavra-chave end. Algumas linguagens, no entanto, utilizam outros
mecanismos. Por exemplo, um código em Python correspondente seria
escrito da seguinte maneira.
N = int(input())
X = 0
for Y in range(1, N + 1):
X = X + Y
print(X)
Embora esses algoritmos são equivalentes, a sintaxe das linguagens de
programação diferentes levaram a programas muito diferentes. Observe
que o conjunto de instruções de uma iteração do for nesse caso é
identificado por meio do recuo (ou indentação). Além disso, utilizamos
um símbolo diferente para representar atribuição: ao invés de :=,
utilizamos =. A escrever ou ler um programa, é imprescindível
atentar-se à sintaxe da linguagem de programação!
Semântica
Além da sintaxe, uma linguagem de programação deve definir uma semântica inambígua, isso é, a linguagem de programação deve definir o que significa cada uma das frases permitidas. Se a sintaxe não tivesse acompanhada de semântica, então o segmento
for Y from 1 to N do
poderia muito bem significar “subtraia 1 de Y e armazene o resultado
em N”. Nada garante, por exemplo, que as palavras for, to e from
tenham o mesmo significado que têm em inglês. Quem garante que o
símbolo := significa atribuição, ou mesmo que + é o operador de
soma? É a semântica que determina o que significa cada frase escrita
em uma linguagem de programação.
Mais do que isso, a semântica deve ser precisa e completa. Mesmo que
as palavras-chaves tenham o significado usual em inglês, pode haver
instruções que são ambíguas ou indefinidas. Por exemplo, se N é um
número inteiro positivo 10, então é razoável presumir que a iteração
do for acima irá executar 10 vezes, com valores de Y = 1, 2, …,
10. Mas se N for -314.1592, qual seria o comportamento esperado?
Talvez o corpo do laço não deveria ser executado nenhuma vez, ou será
que ele deveria ser executado para valores 1, 0, −1, −2, …, -313 e
-314?
Enquanto a definição do que é um programa válido sintaticamente é fácil e, em geral, definido por gramáticas precisas e outros tipos de especificação, como os diagramas acima, definir a semântica de uma linguagem de programação não é uma tarefa trivial. Ela é normalmente definida na documentação fornecida nos manuais de linguagem, que são compostos por capítulos e capítulos de descrição. Pode ser surpreendente descobrir que mesmo linguagens de programação modernas ainda não tenham uma semântica completamente definida.
Compilação
Uma vez que temos um algoritmo escrito em uma linguagem de programação, ainda precisamos de um processo chamado de compilação, que é responsável por converter nosso programa de uma linguagem de programação de alto nível para a linguagem de montagem. Já falamos um pouco sobre a linguagem de montagem antes; essa linguagem contém instruções muito simples e análogas à linguagem de máquina. Ela contém instruções como ler ou armazenar uma palavra na memória, fazer operações aritméticas, desviar o fluxo de execução (goto ou if-then) etc.
Por exemplo, um programa típico
for Y from 1 to N do
{ corpo do laço }
end
seria traduzido um código em linguagem de montagem que se parece com
MVC 0, Y ; guarda a constante 0 na posição Y
LOOP: CMP N , Y ; compara os valores nas posições N e Y
JEQ REST ; se forem iguais, pula à instrução rotulada REST
ADC 1, Y ; adiciona a constante 1 ao valor na posição Y
; ... corpo do laço traduzido ...
JMP LOOP ; volta à instrução rotulada LOOP
REST: ; ... restante do programa ...
Essa tarefa de tradução de uma linguagem de programação de alto nível para uma linguagem de programação de baixo nível é realizada por um programa bem sofisticado chamado compilador. O compilador é normalmente fornecido pelo desenvolvedor da linguagem ou pelo vendedor do hardware e deve ser específico para cada processador. Depois de obtido um programa em linguagem de montagem, ainda é necessário convertê-lo em linguagem de máquina. Isso normalmente é feito automaticamente pelo compilador, que invoca uma série de programas de sistemas (o chamado software básico), como montadores, carregadores etc.
Esses programas de sistema têm uma série de funções, com o papel de facilitar um conjunto de modos de operação de alto nível do computador. Isso permite isolar o usuários de vários detalhes de baixo nível envolvidos. Um dos principais programas de sistema é o chamado sistema operacional, que é responsável por gerenciar recursos e periféricos, fornecendo ao programa de usuário esses modos de operação de alto nível. Simplificadamente, podemos então entender a execução de um programa em camadas, em que camadas mais acima têm abstrações de alto nível, enquanto camadas mais abaixo têm abstrações mais próximas do hardware.
| Programas de Aplicação |
| Compiladores |
| Sistema operacional |
| Hardware |
Interpretação e execução imediata
Existe ainda uma outra maneira de executar programas escritos em uma determinada linguagem de programação. Ao invés de converter o código-fonte do programa em uma linguagem de máquina, para depois executar o programa traduzido, podemos executar cada instrução da linguagem de programação de alto nível assim que ela for reconhecida. Assim, ao invés de usarmos um compilador, usamos um programa que é responsável por essa tradução local e execução imediada, chamado de interpretador.
A forma com que cada interpretador é criado pode variar bastante de implementação para implementação. Em muitos casos, você pode imaginar simplesmente que o interpretador realiza todo o processo de compilação e executa o programa obtido diretamente, sem a necessidade de invocá-lo. Algumas vezes, no entanto, as instruções são executadas à medida em que as escrevemos. Isso acontece, por exemplo, quando utilizamos o modo interativo de linguagens de programação de script, como Python, Ruby, etc.
Existem algumas razões para se criar um interpretador ao invés de um compilador, entre as quais:
-
normalmente é mais fácil escrever um interpretador para uma linguagem de programação, do que um compilador completo;
-
é mais fácil entender o que está acontecendo durante a execução do programa em linguagens interpretadas, particularmente quando trabalhando interativamente através de um um terminal conectado a tela do computador, o que permite que inspecionemos os valores das variáveis à medida em que o programa executa.
Do problema à execução
Desde o conhecimento do problema até a execução do programa no computador para obter uma solução, existe um processo que passa por diversas etapas. Por isso, é importante entender bem esse processo e realizar bem cada uma das etapas, sem tentar pular passos. Faça sempre o seguinte:
-
Entenda o problema! Descreva qual é o conjunto de entradas válidas e qual é o conjunto de saídas. Procure especificar também qual saída deve corresponder a cada entrada válida.
-
Estude o problema e tente resolver algumas instâncias desse problema. Tome nota de que passos você realiza. Com isso, você terá uma ideia de como resolver uma instância genérica do problema.
-
Tente expressar suas ideias na forma de um algoritmo. Lembre-se sempre de utilizar apenas instruções elementares. Também, sempre teste seu algoritmo para instâncias pequenas, até se convencer de que ele está correto.
-
Apenas depois de ter escrito e testado seu pequeno algoritmo, reescreva-o em uma linguagem de programação.
-
Você irá compilar o código-fonte e executar o programa criado, ou irá interpretar o código-fonte diretamente, dependendo da linguagem. Você pode encontrar uma série de erros:
-
Muitas vezes, haverá erros de sintaxe e você precisará corrigir seu programa para que ele seja um texto válido.
-
Outras vezes, embora o programa seja válido sintaticamente, ocorrerão erros no momento em que você o executa. Isso pode acontecer por uma série de motivos. Esses erros são chamados erros de tempo de execução. Você precisará revisar seu código-fonte e voltar ao passo 4.
-
Finalmente, pode ser que não haja erros de sintaxe e nem ocorram erros de tempo de execução, mas, mesmo assim, os resultados obtidos pelo seu programa não estejam corretos. Quando isso acontece, dizemos que há erros de lógica no seu programa. Eles pode ocorrer porque você escreveu um código-fonte que não corresponde ao seu algoritmo, ou porque seu algoritmo está incorreto. Se for esse o caso, então será preciso voltar ao passo 3.
-
A figura extraída do livro representa o processo de compilação e execução.
