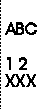Para a entrada elementar de dados através do dispositivo
padrão de entrada, que, via de regra, é representado
pelo teclado, existem os comandos read
e readln.
Para cada identificador da lista de parâmetros (exceto o
primeiro, caso represente um fluxo de entrada), busca-se
um valor no fluxo de entrada representado na forma simbólica.
Se encontrado, ele é convertido em um valor interno e armazenado
na posição de memória representada pela
variável em questão.
Para uma variável inteira, por exemplo, procura-se uma
seqüência de caracteres que representem os dígitos
de um inteiro eventualmente precedidos por um sinal +
ou -. Neste caso são descartados eventuais
caracteres brancos e, a partir do primeiro caractere não
branco, a rotina de leitura assume que encontrou uma cadeia de
caracteres que está em acordo com a sintaxe de inteiros. Se
isto não for o caso, ocorre um "erro fatal" e a
execução do programa é interrompida.
Se, por outro lado, a rotina encontrou um caractere que atenda
à sintaxe de um inteiro, ela continua a consumir
caracteres até que encontre algo diferente, como um
caractere branco, por exemplo.
Durante o processo, a seqüência de caracteres,
que satisfizer a sintaxe de um inteiro, é convertida
em um valor binário. Ao final do processo, o valor
binário resultante é armazenado na posição
correspondente à variável inteira para a qual a
rotina de entrada buscou um valor.
Se tivermos, por exemplo, um fluxo de entrada

e o comando
read(k);
é executado, onde k é uma variável
inteira, então o fluxo ficará na seguinte
situação

e a posição de memória correspondente à
variável k conterá o valor binário
10010. Os caracteres anteriores ao cabeçote representado
pelo triângulo já foram consumidos e não podem ser
lidos novamente.
Acima falamos que caracteres brancos são descartados. Isto
não só ocorre estritamente com o caractere
branco (o caractere de índice 32 na tabela ASCII),
mas também com caracteres de formatação
de texto como o de tabulação (o de índice
25), o de mudança de linha (LF:
line feed, de índice 10) e o de "retorno
de carro" (CR: carriage return,
de índice 13). Portanto, quando falamos no descarte de
caracteres branco, estamos falando no "sentido amplo" que
abrange também aqueles na categoria de caracteres de
formatação de texto.
Voltando ao exemplo acima, se tivermos uma variável inteira
m e executarmos o comando
read(m);
então o fluxo ficará no seguinte estado

e a posição de memória correspondente à
variável m conterá o valor binário
10100.
O esquema acima funciona para valores de tipos básicos,
exceto quando da leitura de caracteres para variáveis
do tipo char. Neste caso, os caracteres no
fluxo de entrada são consumidos seqüencialmente
sem o descarte dos caracteres branco no "sentido amplo."
Isto é, se for solicitada a leitura de um caractere
e o próximo no fluxo de entrada for um branco no
"sentido amplo," então ele é lido e é
efetuada a atribuição correspondente à
variável para a qual foi lido o valor em questão.
A diferença básica do readln
e read é que, além de consumir a
quantidade de caracteres necessária para determinar
os valores das posições de memória
associadas aos parâmetros do comando, o readln
ainda descarta todos os caracteres depois do último
consumido até, inclusive, os caracteres de formatação
de mudança de linha geradas pela tecla ENTER
(isto é, o CR seguido do LF).
Na situação resultante acima, se executássemos
agora o comando
read(c);
onde c representa uma variável do tipo char,
então seria lido o caractere logo após o cabeçote
e c assumiria o valor correspondente ao caractere
CR ao invés do caractere S, como
pretendíamos.
Portanto, para simplesmente descartar o resto de uma "linha
de entrada" e posicionar o cabeçote no "início
da linha seguinte," podemos executar o comando readln
sem parâmetros, quando estamos manipulando o dispositivo
padrão (teclado), ou com apenas um parâmetro que
corresponda ao identificador do arquivo de cujo fluxo
estamos lendo.
Para ler o valor S na situação resultante
acima, teríamos que eliminar os caracteres de controle
para então lermos o caractere desejado. Isto pode ser
feito através da execução dos comandos
readln;
read(c);
ou
readln;
readln(c);
No primeiro caso, o fluxo ficaria na situação

e , no segundo, na situação

Quando misturamos a leitura de valores do tipo char
(um caractere para representar uma seleção de
uma opção em relação a um leque de
alternativas, por exemplo) com valores de outros tipos,
precisamos, portanto, tomar cuidado. Suponhamos que foi lido um inteiro
que o usuário forneceu ao sistema, via teclado, seguido
por um ENTER, e que após esta
operação queiramos ler uma opção como
S ou N fornecida em decorrência
da solicitação "Você que continuar
(s/n)?", por exemplo. Se o primeiro dado foi lido com um
read apenas, os caracteres de controle que indicam
o final de linha que seguem o inteiro lido, isto é, o
CR e o LF, continuam lá no
fluxo de entrada e a seguir é lido o CR
ao invés do S ou N como
esperávamos.
Para eliminar o problema acima, precisamos descartar o resto
da linha anterior e posicionar o cabeçote no início
da linha seguinte através da execução
do comando readln.
Ao digitarmos dados via teclado eles são "ecoados" na tela do
monitor do computador, isto é, eles são mostrados na
tela conforme vão sendo digitados. Enquanto não
pressionarmos a tecla ENTER, o processo de leitura não
não é disparado, O programa suspende a execução
do comando read ou readln que
está demandando dados do usuário. Ao ocorrer o disparo
via o pressionar da tecla ENTER, a execução
do programa é retomada neste ponto.
O dispositivo padrão de saída é, via de regra, o
monitor do computador. A saída neste dispositivo é gerada
com os comandos write e writeln.
Estes comandos adicionam caracteres ao fluxo de dados associado ao
dispositivo padrão, onde são devidamente visualizados.
Os dois comandos adicionam os caracteres correspondentes à
representação simbólica dos valores associados
aos seus parâmetros.
Além deste comportamento, o comando writeln
ainda adiciona os caracteres CR e LF ao fluxo de
saída e causa com isto uma mudança de linha na
visualização dos dados na tela do monitor do computador
após o último caractere escrito pelo comando. O cursor
na tela indica a próxima posição para a escrita
de novos valores.
Suponha que a variável k contenha o valor 18
(10010, em binário) e a variável m o valor
20 (10100, em binário). Se você executar
o comando
write(k,m);
e o cursor se encontrar no início de uma linha, então os
valores binários das variáveis são convertidos para
a sua representação simbólica e você
terá, nesta linha, o seguinte texto
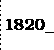
onde _ representa a posição do cursor após
esta operação. Conforme você pode observar, os dois
valores encontram-se justapostos. Se você quiser evitar isto,
você terá que escrever um ou mais brancos entre estes dois
valores. Isto pode ser feito da seguinte forma:
write(k,' ',m);
O segundo parâmetro representa este espaçamento de uma
posição. Na situação acima, você
obterá a seguinte linha de saída:
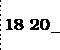
Se você tivesse optado pelo comando writeln ao
invés do comando write, o comando executado seria
writeln(k,' ',m);
e a saída correspondente seria
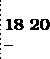
Como você pôde observar nos exemplos acima, o espaço para
representar os valores dos parâmetros na sua forma simbólica
é a menor possível e, portanto, o espaço ocupando
depende destes valores. Se você quiser ter mais controle sobre o
espaço a ser utilizado, você usa parâmetros
formatados.. Por exemplo, o comando
write(k:5);
indica que a representação simbólica do valor de
k será utilizado um "campo" de 5 posições.
Neste campo também deverá ser acomodado um possível
valor negativo. Se menos do que 5 posições são
necessárias para a representação do valor de
k, então a representação é alinhada
à esquerda e as posições não ocupadas à
direita são "preenchidas" com o caractere branco. A
formatação para valores inteiros é indicada pelo
caractere : seguido de uma expressão que deve resultar em
um valor inteiro.
Para reais, temos duas expressões, cada uma precedida por um
caractere :. Neste caso, o valor da primeira expressão
define o tamanho do campo, onde será representado o valor, e
o segundo o numero de casas decimais desejadas. No campo
dimensionado pelo valor da primeira expressão devem ser acomodados
o sinal do número, a parte inteira, o ponto decimal e a parte
fracionária.
Suponha que x contenha o valor 17.527. Se o cursor
estiver no início de uma linha e você executar o comando
writeln(x:5:2);
então você obterá o seguinte resultado:
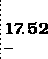
como no caso de inteiros, valores que não ocuparem todo o campo
alocado são precedidos por caracteres brancos. Se, por outro lado,
o campo estiver subdimensionado, tanto no caso de inteiros como de reais,
então o campo é preenchido com asteriscos.